数据技术应用概论
第一章 绪论
数据素质培养意义
数据技术
数据科学应用体系框架
第二章 计算机信息系统
计算机信息系统的构成
计算机信息系统技术路线
第三章 抽样技术
抽样技术概述
网络调查和社会调查
抽样学习
抽样技术的基本概念
第四章 网络爬虫与文本数据生成
网络爬虫概述
网络爬虫技术操作
文本数据生成
第五章 数据库技术
数据库技术概述
数据库系统开发
关系数据库
数据仓库
第六章 SQL语言
SQL概述
SQL关系定义
SQL查询基本结构
数据库修改
视图
第七章 数据预处理技术
数据预处理概述
数据清理
数据集成
数据规约
数据变换
第八章 回归模型
回归模型的基础知识
最小二乘法
其他常用回归模型
第九章 Logistic建模技术
基础知识
梯度上升算法
第十章 关联规则挖掘
关联规则挖掘的基础知识
关联规则挖掘的 Apriori 算法
其它常用关联规则挖掘算法
第十一章 决策树分类规则
决策树分类规则的基础知识
决策树分类规则挖掘的ID3算法
几种常用的决策树
第十二章 K-平均聚类
基础知识
基于划分的K‐平均聚类算法
其他常用的聚类
第十三章 神经网络模型
神经网络模型的基础知识
误差逆传播算法
其他常用的神经网络算法
第十四章 支持向量机
支持向量机的基础知识
支持向量机的SMO算法
其他常用的支持向量机算法
第十五章 集成学习算法
集成学习算法的基础知识
随机森林算法
其他常用的集成学习算法
第十六章 数据可视化
数据可视化的基础知识
可视化设计基础
数据可视化工具
-
+
首页
文本数据生成
## 4.3 文本数据生成 - 文本是人类采用文字语言描述事物的一种基本形式,包括书籍、学术期刊、报刊文字新闻、数字图书馆、电子邮件和Web页面等等。 - 结构化数据概念的提出与流行是来自计算机数据库技术对数据处理的分类,称可直接由关系数据库存储处理的数字、文字符号等为结构化数据,不能直接存储处理的数据为非结构化或半结构化数据,包括图形、图像和音频,以及统称文本的采用文字语言描述的各种载体。非结构化数据要通过计算机进行处理,需要将其转换为结构化数据。图形、像、音频以及文本的结构化转换需要不同的的技术方法来实现。 - 本节仅介绍中文文本数据的结构化转换,该数据转换的过程称为文本数据生成。主要包括分词和文本表示两个知识点。 ### 4.3.1 中文分词 - 中文分词属于自然语言处理技术范畴, - `自然语言处理`(NLP,Natural Language Processing)是用机器处理人类语言(有别于人工语言,如程序设计语言)的理论和技术。自然语言处理是人工智能的一个重要分支。和大部分西方语言不同,书面汉语的词语之间没有明显的空格标记,句子是以字串的形式出现。 - 因此对中文进行处理的第一步就是进行自动分词,即将字串转变成词串(计算机在词与词之间加上空格或其他边界标记),这就是`中文分词`。 众所周知英文是以单词为单位的,词与词之间是依靠空格分隔,而中文是以字为单位,句中所有的字连起来组成序列才能描述一个意思,词与词之间没有任何空格之类的显式标志指示词的边界。 例如: - 英文 “I am a student” - 中文 “我是一个学生” 计算机通过空格知道student是一个单词,但却不能明白“学”和“生”两个字合起来表示一个词。把中文汉字序列切分成有意义的词就是中文分词,有些人也称为切词。 例如:“我是一个学生” 分词结果:我/是/一个/学生。 对于一句话,人们可以通过自己的知识来明白哪些是词,哪些不是词,但如何让计算机也能理解,其处理过程就是`分词算法`。 - 经过:1983年国内外开始研究中文分词,提出许多有效算法。一般而言,根据不同应用,汉语分词的颗粒度大小不同。例如机器翻译中,颗粒度应该大一些,“北京大学”不能被分成两个词。而语音识别中,“北京大学”一般被分成两个词。在很多应用中,分词准确性和分词速度都非常重要。例如搜索引擎中根据用户提供的关键词进行搜索任务,搜索引警需要在后台对亿计的网页内容进行处理,将中文内容进行分词跟用户关键词进行匹配,如果分词时间过长,严重影响搜索引擎内容更新速度,影响用户体验感。对于搜索引擎而言,如果分词速度太慢,即使准确性再高,也是不可用的。分词的准确性和速度都需要达到很高要求。 #### 中文分词的==主要难点==: - 分词规范问题 “词”这个概念一直是汉语语言学界纠缠不清而又挥之不去的问题。“词是什么”(词的抽象定义)及“什么是词”(词的具体界定),这两个基本问题有点飘忽不定,迄今拿不出一个公认的、具有权威性的词表来 主要困难出自两个方面:一方面是单字词与词素之间的划界,另一方面是词与短语(词组)的划界。此外,对于汉语“词”的认识,普通说话人的语感与语言学家的标准也有较大的差异。有关专家的调查表明,在母语为汉语的被试者之间,对汉语文本中出现的词语的认同率只有大约70%,从计算的严格意义上说,自动分词是一个没有明确定义的问题。 - 歧义切分问题 歧义字段在汉语文本中普遍存在,因此,切分歧义是中文分词研究中一个不可避免的“拦路虎” 1. (交集型切分歧义) 汉字串AJB如果满足AJ、JB同时为词(A、J、B分别为汉字串),则称作交集型切分歧义。此时汉字串]称作交集串。 如“结合成”、“大学生”、“师大校园生活”、“部分居民生活水平"等等。 2. (组合型切分歧义) 汉字串AB如果满足A、B、AB同时为词,则称作多义组合型切分歧义。 “起身":(a)他站|起|身|来。(b)他明天|起身|去北京。 “将来":(a)她明天|将|来|这里作报告。(b)她|将来|一定能干成大事。 - 未登录词问题 未登录词又称为生词(unknown word),可以有两种解释:一是指已有的词表中没有收录的词;二是指已有的训练语料中未曾出现过的词。在第二种含义下,未登录词又称为集外词(outof vocabulary,OOV),即训练集以外的词。通常情况下将OOV与未登录词看作一回事。对大规模真实文本来说,未登录词对于分词精度的影响远远超过歧义切分。 未登录词可粗略分以下几类:`新出现的普通词汇、专有名词、专业名词和研究领域名称、其他专用名词`。 #### 中文分词的==基本原则==: 1.语义上无法由组合成分直接相加而得到的字串应该合并为一个分词单位。 - 例如 :不管三七二十一(成语),或多或少(副词片语),十三点(定量结构),六月(定名结构),谈谈(重叠结构,表示尝试),辛辛苦苦(重叠结构,加强程度),进出口(合并结构) 2.语类无法由组合成分直接得到的字串应该合并为一个分词单位。 - (1)字串的语法功能不符合组合规律,如:好吃,好喝,好听,好看等 (2)字串的内部结构不符合语法规律,如:游水等 #### 中文分词的==辅助原则==: - 1. 有明显分隔符标记的应该切分之 - 2. 附着性语素和前后词合并为一个分词单位。 - 3. 使用频率高或共现率高的字串尽量合并为一个分词单位 - 4. 双音节加单音节的偏正式名词尽量合并为一个分词单位 - 5. 双音节结构的偏正式动词应尽量合并为一个分词单位 - 6. 部结构复杂、合并起来过于几长的词尽量切分。 #### 中文分词常用方法 1. `词典匹配分词法` - 词典匹配分词法是20世纪80年代提出的,又称机械分词法。 - 基本思想:事先建立一个词库,其中包含所有可能出现的词条。给定待分词的汉字串,按照某种确定原则切取其子串。如果该子串与词库的某词条相匹配,则该子串是词;继续分割剩余的字串,直到剩余字串为空。否则,该子串不是词,重新切取子串进行匹配。 - 词典匹配是分词中`最传统最常用`的办法。 - 即便其后提到基于统计学的分词方法,词条匹配也通常是重要的信息来源,通常是在匹配方式方面会加入一些启发式规则。按照扫描方向的不同分为正向匹配和逆向匹配,按照不同长度优先分配的情况,分为最大匹配和最小匹配,按照与词性标注过程是否相结合,分为单纯分词方法和分词与标注结合方法等。 `正向最大匹配分词法` - 正向最大匹配分词法是以词典为依据,取词典中最长单词字数为起始字长的扫描串,然后逐字递减,在对应的词典中查找。如“我们是中华人民共和国的公民”。 如果在字典中匹配,可能被切分成“我们/是/中华/人民/共和国/的/公民”,一共包含7个词。 如果在字典中存在最大匹配项“中华人民共和国”,则优先选择其作为一个词进行切分。该句子就被切分为“我们/是/中华人民共和国/的/ 公民”逆向最大匹配分词法的策略与正向最大匹配分词法相同,区别在于扫描方向与正向最大匹配分词方法相反,从句子的结尾开始扫描,直至句首。 优点: - 程序简单易行,开发周期短; - 仅需要很少的语言资源(词表),不需要任何词法、句法、语义资源缺点; - 歧义消解的能力差; - 切分正确率不高,一般在85 % 左右。 歧义词如“联合国/内”亦可切分为“联合/国内”。`IK Analyzer分词法`就是`基于词典匹配`的分词方法。 2. `统计分词法` - 统计分词的基本原理是依据字串在词库中出现统计频率来判断是否成词。词是字的组合,相邻字同时出现次数越多,越可能构成一个词。字与字相邻共现频率或概率能够较好反映它们成词的可信度。 - 统计分词方法一般先通过大规模语料训练统计模型参数。在分词阶段利用模型计算各种可能分词结果出现概率,将概率最大的分词结果作为最终结果。 例如N-gram模型,就是基于统计的分词模型。 3. 结巴分词 - 结巴分词(Jieba)综合词典匹配和统计分词的优点。拥有训练后录入了的大量词条的基本库;基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(Directed Acyclic Graph,DAG),采用了动态规划査找最大概率路径,找出基于词频的最大切分组台 - 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。 - 结巴分词有三种分词模式,分别是`精确模式、全模式和搜索引擎模式`。 精确模式是依据最高精度进行分词,适用于文本分析; 全模式扫描字串中全部可能词条,速度很快; 搜索引擎模式基于精确模式对长词切分,可用于搜索引警分词。 方便理解,下面用一个示例来解释这三种模式的区别: - 例子: “我来到北京清华大学” - 分词结果: 全模式:我/来到/北京/清华/清华大学/华大/大学。 精确模式:我/来到/北京/清华大学。 搜索引警模式:我/来到/北京/清华/清华大学/华大/大学/北京清华大学 ### 4.3.2 向量空间模型 #### 1.向量空间模型(vector space model,VSM)是自然语言处理模型。 - 计算机无法直接理解自然语言语义。`文本数据生成的目标`就是将文本转化为计算机能够处理的结构化数据,从而帮助计算机更好的从文本中挖掘到有价值的信息。因此要求计算机能够真实反映领域、主题及结构等文本特征,同事能高效处理文本特征信息的约束。 - 应对这一约束思路是,采用文本抽取的特征词出现频率作为其文本特征量化标识的基础,以系列特征词及相应量化标识,构建表示文本信息的空间向量模型,将文本内容处理转化为空间向量运算,实现计算机文本识别与数据处理。 如:以空间相似度表达语义相似度,度量文本相似性等。 这里的向量空间模型的文本特征是以权值向量表示的,实际操作主要解决==特征选取==和特征权重计算问题。 #### 2.独热码表示(one-hot)常用于自然语言的离散特征取值处理。 如:文本分类、推荐系统及垃圾邮件过滤等场景。 - 独热码表示技术的思路:经编码的N位状态寄存器(StatusRegister)对应向量的每个状态,文本特征状态基于给定标准确定,其中只有一个特征标识为1,其余均标识为0进入状态寄存器,实现文本特征分类。 - 相关标准可以是基于需求目标主观构造,也可采用支持向量机(Support Vector Machine,SVM)神经网络(Neural Network,NN)、最近邻算法(K-nearest Neighbor,KNN)等得到。 one-hot表示`向量长度为测度文本对象词库的词数目`,如文本语料集合(词库)有n个词,则一个词采用长度为n的向量表示。对于第i(i-0,…,n-1)个词,向量的第i个分量值为1,其他分量值都为0,通过向量[0,0,1..,0,0]唯一表示一个词。 如: text1:我爱中国 text2:爸爸妈妈爱我 text3:爸爸妈妈爱中国 对语料库分词,首先统计出整个词表,获取所有词,词编号分别为: - 1:我; 2:爱; 3:爸爸; 4:妈妈; 5:中国 词表中该位置的词在文本中出现了就记1,不出现就记0,每个文本表示成词表维度的向量。 使用`布尔特征`对每段话构建特征向量,得到的特征向量为: - V(我爱中国)=[1,1,0,0,1]; V(爸爸妈妈爱我)=[1,1,1,1,0]; V(爸爸妈妈爱中国)=[0,1,1,1,1]。 - 原理如图所示: 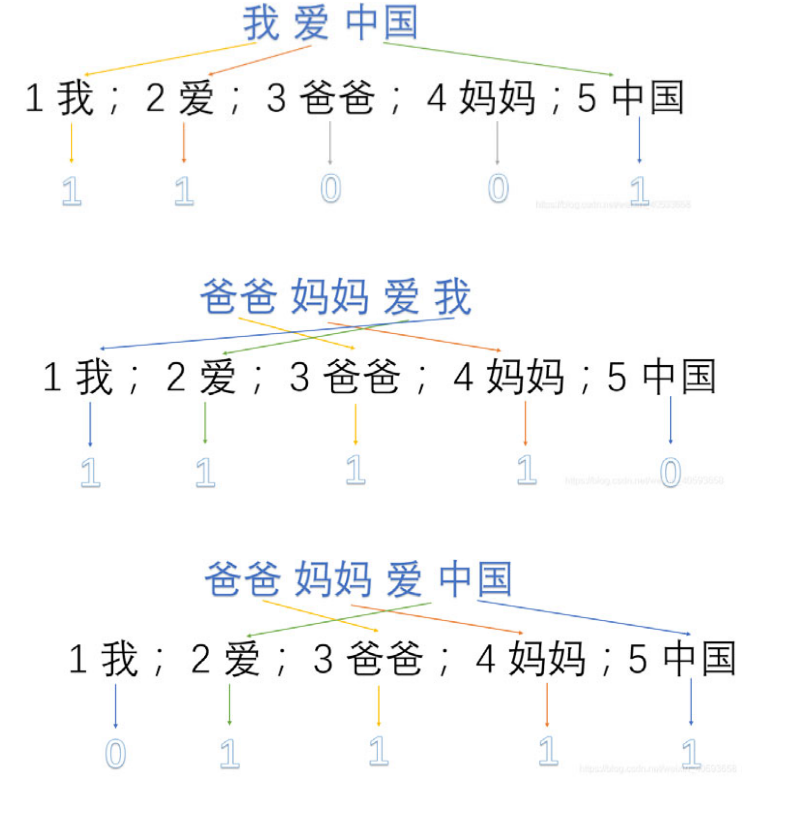 ### 4.3.2 向量空间模型 - 优点: 1、解决了分类器处理离散数据困难的问题 2、一定程度上起到了扩展特征的作用 - 缺点: 1、每个单词的编码维度定义为整个词汇表,造成维度过大,编码稀疏,计算成本提高问题。 2、存在单词间相互独立强制性假设,导致无法识别单词间联系程度,丢失位置信息 ### 4.3.3 特征权重计算 #### 1、布尔权重 文本被表示为一组特征项及其权重的集合,对于每一个特征项而言,其在文本中只存在两种状态:`出现或不出现`,因此,以该特征项是否在文本中出现为依据来计算特征项的权重,每一个权重可以取两个值:`“0”或“1”`,对于特征$$t_i$$,特征权值$$w_i$$公式如下: ```latex w_i\;=\;\left\{\begin{array}{l}1,if\;t_i\;occurs\;in\;d\\0,else\end{array}\right. ``` - 优点:简单、易理解、易于表达同义关系和词组。 - 缺点:不能表示特征相对文本的重要性,缺乏定量分析和灵活性,并不能表示模糊匹配。 #### 2、绝对词频权重 绝对词频权值法是根据特征项在文本中的出现频度来确 定其重要程度的一种加权方法,即$$w_i = tf_i$$,其中$$tf_i$$为特征项$$t_i$$中的绝对词频。 #### 3、TF/IDF权重 - TF/DF权重是依据特征项在文本中出现的统计频率。 - 文本范围对权重产生决定性影响。特征项在单个文本中的权重可视为局部权重;在一个领域文本集的权重表现为全局权重。 - 某一特征项在一个文本中出现多次,其在同类文本中也可能出现多次。反之亦然。向量空间模型采用词频TF作为权重,体现同类文本的共性。如果该特征项对大多数文本的重要程度相同时,则会弱化对文本区分能力。`TF-IDF采用相反策略`,基于某一特征项出现的文本频率越小,该特征的文本类别区分能力越大这个认知,引入逆文本频率IDF的概念,以TF和IDF的乘积作为文本向量空间的权重。 - TF/IDF计算公式:$$w_{ij} = tf_{ij} \times idf_{i} = tf_{ij} \times log(m/m_i)$$ 其中,$$tf_{ij}$$表示特征项$$t_i$$的词频, 用于计算$$t_i$$描述文本内容的能力;$$idf_{ij}$$表示逆文本频率,用于计算$$t_i$$区分不同文本的能力,$$m$$表示文本集中的文本总数,$$m_i$$表示包含特征项$$t_i$$的文本数。 - 特征项在文本中出现次数越多,它对文本的贡献越大,二者成正比例关系。 - 权重与整个文本集中出现该特征项的文本数成反比,即一个特征项在越多的文本中出现,说明它的分布越均匀,它的类别区分能力越弱。 TF-IDF示例: 假设文本集D中包含1000000篇文本,其中某一篇文本采用中文分词方法后获得的总词语数是100个,而词“数据挖掘”在该篇文本中出现了3次,那么“数据挖掘”一词在该文本中的词频$$tf_{ij} = 3/100 = 0.03$$。如果“数据挖掘”一词在1000篇文本中出现过,则逆文本频率$$idf_{i} = log(10000000/1000) = 4$$,最后的TF-IDF权重为$$0.03 \times 4 = 0.12$$ ### 4.3.4 其他语言模型 1、==Word2vec== - Word2vec(word to vector)把文本的文字转化为向量表示,是2013年Google开源的一个词嵌入(word embedding)工具。 - Word2vec主要包含两个模型,连续词袋模型(CBOW)与跳字模型(skip-pran ) `连续词袋模型`根据输入的上下文作为输入来预测当前单词。 `跳字模型`输入特定词的词向量,输出特定词对应的上下文词向量。 - Word2vec考虑上下文关系,嵌入的维度更少、速度更快、通用性更强,效果更好,常用于文本相似度检测、文本分类、情感分析、推荐系统以及问答系统等句子级与篇章级自然语言处理任务。 - Word2vec无法解决一词多义问题,无法针对特定任务做动态优化,并且它的相关上下文不能太长。 2、==循环神经网络== - 循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。 - 相比一般的神经网络来说,能够处理序列变化的数据如某个单词的意思会因上文内容不同而有不同含义,RNN能很好地解决这类问题。 例如,预测“the clouds are in the sky”这句话的最后一个字,不需要其他的信息,通过前面语境就能预测最后一个字应该是sky。在这个例子中相关信息与该信息位置距离近,RNNs能够学习利用以前的信息对当前任务进行相应操作。 3、==长短期记忆模型(LSTM)== 长短期记忆模型(long short-term memory,LSTM)是一种特殊的循环神经网络主要是为了解决长序列训练过程中的`梯度消失和梯度爆炸问题`。 相比普通的循环神经网络,长短期记忆模型能够在`更长的序列中有更好的表现`。 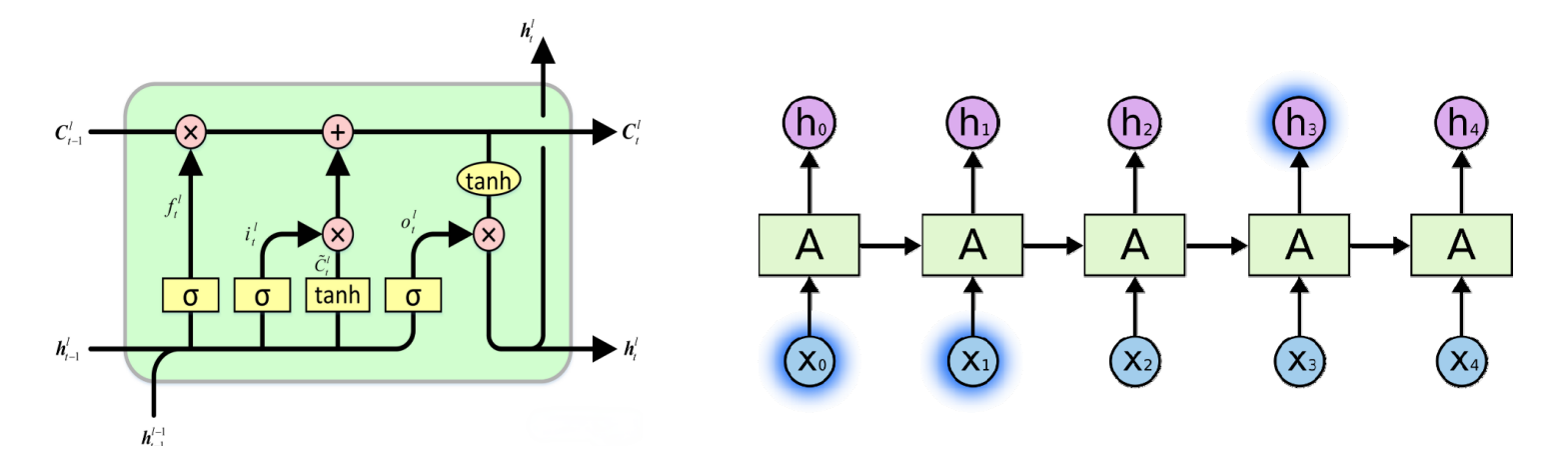 4、==BERT模型== - BERT模型(bidirectional encoder representation from transformers)是一种基于注意力机制的自编码语言模型。 - 分为语言模型预训练和语言模型拟合训练两阶段。 `语言模型预训练`通过大量的语料对模型进行训练,主要采用双向语言模型技术、MLM技术以及NSP机制。BERT在训练时利用上下文信息预测被“[Mask]”遮罩位置的单词。 在`语言拟合训练`中,利用NSP利用己知的一句文本内容预测下一句内容。 在实际应用中,BERT模型生成的向量能够包含丰富的特征信息,对同一个词语在不同语境中的区分度更好。使用这种预训练任务在很多下游任务中表现出色,如问答系统(QA),自然语言推断(NI)等。
张龙
2024年7月10日 14:57
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码