人工智能训练师(四级)
模块0 人工智能训练师职业认知
学习单元1 人工智能概论
学习单元2 人工智能训练师岗位认知
模块1 数据采集和处理
课程1-1 业务数据采集
学习单元1 文本与图片数据采集(爬虫)
学习单元2 视频数据采集
学习单元3 语音数据采集
课程1-2 业务数据处理
学习单元1 文本数据清洗
学习单元2 图像数据清洗
模块2 原始数据标注
学习单元1 文本数据标注
学习单元2 图像数据标注
学习单元3 语音数据标注
模块3 使用Excel进行分类统计
模块4 数据归类和定义
学习单元1 聚类分析
学习单元2 回归分析
学习单元3 关联分析
模块5 标注数据审核
学习单元1 标注数据质量检验基础知识
学习单元2 图像和视频标注数据质量检验
学习单元3 语音标注数据质量检验
学习单元4 文本标注数据质量检验
模块6 智能系统运维
学习单元1 智能系统运维基础
学习单元2 系统功能日志维护
学习单元3 常见智能系统介绍
学习单元4 使用Docker进行系统安装部署
附加0 工作中常用的人工智能软件
-
+
首页
学习单元1 聚类分析
## 1.聚类分析的基本概念 聚类分析是一种将相似的对象或数据点分组的技术,以便更好地理解和分析数据。 ### 1.1聚类分析的分类 - 根据聚类方法的不同,可以分为基于距离的聚类、基于密度的聚类和基于模型的聚类等: ```mindmap # 聚类分析的类别 ### 基于距离 ### 基于密度 ### 基于模型 ``` - 基于距离的聚类: - 含义: 基于距离的聚类方法是根据数据点之间的距离来将它们划分为不同的簇。通常假设簇内的数据点彼此之间的距离较近,而不同簇之间的距离较远。 - 例子: 包括 K-means 聚类和层次聚类。K-means 聚类通过迭代优化簇的中心,使得每个数据点到其所属簇的中心距离最小化。层次聚类则通过逐步合并或分割簇来形成一个层次结构。 - 基于密度的聚类: - 含义: 基于密度的聚类方法是根据数据点的密度分布来划分簇,通常适用于数据点分布不均匀、簇的形状复杂或噪声较多的情况。 - 例子: 包括 DBSCAN(基于密度的空间聚类)和 OPTICS。DBSCAN 通过设定一个领域半径和最小邻域密度来定义核心点、边界点和噪声点,从而识别出不同密度的数据簇。 - 基于模型的聚类: - 含义: 基于模型的聚类方法假设数据集是由某种概率分布或潜在结构生成的,通过拟合这些模型来进行聚类。 - 例子: 包括高斯混合模型(GMM)和概率潜在语义分析(LDA)。GMM 假设数据点是从多个高斯分布中抽取而来的,通过最大化似然或期望最大化算法来估计每个分布的参数,从而确定数据的簇。LDA 则是一种用于文本数据的聚类方法,将文档分配到多个主题中,每个主题可以看作是一个概率模型。 ### 1.2聚类分析的目的 - 数据分组:聚类分析的目的是将相似的数据点分组,以便更好地理解和分析数据。 - 特征提取:聚类分析可以帮助我们提取数据的关键特征,以便更好地理解和分析数据。 - 数据可视化:聚类分析可以帮助我们更好地可视化数据,以便更好地理解和分析数据。 ### 1.3聚类分析的应用场景 聚类分析在各种领域和应用中都有广泛的应用,一些主要的应用场景包括但不限于: - 市场分割与定位:通过聚类分析可以识别市场中具有相似需求和特征的群体,帮助企业制定针对性的市场营销策略和产品定位。 - 客户分群与行为分析:将客户按照购买行为、偏好等特征分成不同的群组,有助于个性化推荐、客户关系管理(CRM)和精准营销。 - 医学与生物信息学:在基因组学、蛋白质组学等领域,通过聚类分析可以发现基因或蛋白质表达的模式,帮助诊断疾病或发现新的药物靶点。 - 图像分析与计算机视觉:在图像处理中,聚类分析可以用来分割图像、识别相似的图像区域或对象,例如在物体识别、人脸识别等领域。 - 社交网络分析:在社交网络或互联网用户行为分析中,聚类分析可以帮助发现用户群体、社区结构、趋势和影响力人物。 - 地理信息系统(GIS):在地理空间数据分析中,聚类分析可以用于区域分类、地理区域划分、资源分布分析等。 - 文本挖掘与信息检索:聚类分析可以用来对文本数据进行主题分析、文档分类或发现文本集合中的模式和趋势。 ## 2.聚类分析的主要方法 ### 2.1K-means聚类 - K-means聚类是一种常用的聚类方法,它通过将数据点划分为K个不同的簇,使得每个簇内的数据点相似度较高。 - K-means聚类方法简单、快速,适用于大数据集。 #### 2.1.1K-means逻辑步骤 - 随机选择K个初始簇中心。 - 对于数据集中的每一个样本,计算其到每一个聚类中心的距离,然后将其分配到最近的聚类中心所对应的类别。 - 根据新的分配结果,重新计算每个类别的聚类中心。 - 迭代重复上述步骤直到满足终止条件。 #### 2.1.2K-means聚类的工具 - Python相关工具: - scikit-learn:scikit-learn是一个广泛使用的Python机器学习库,提供了高效的 K-means聚类算法实现,支持多种初始化方法和优化选项。 - TensorFlow和Keras:TensorFlow 和其高级API Keras提供了K-means聚类的实现,特别适合在大规模数据集上进行分布式计算和深度学习模型集成。 - PyTorch:PyTorch也支持K-means聚类,尤其在需要GPU加速时表现出色。 - R 语言工具: - stats包:R语言的基础包 stats中提供了K-means的实现,是R中最常用的聚类算法之一。 - cluster包:另外一个常用的 R 包,专门用于聚类分析,包含了多种聚类算法的实现,其中也包括 K-means。 - 其他工具和平台: - Apache Spark:Apache Spark 提供了分布式数据处理和机器学习库 MLlib,包括了 K-means 的分布式实现,适用于大规模数据集。 - MATLAB:MATLAB 提供了多种聚类算法的实现,包括 K-means,适合于快速原型设计和数据分析。 - Weka:Weka 是一个流行的机器学习工具集,也包含了 K-means 聚类的实现,适合于数据挖掘和实验设计。 #### 2.1.3 K-means应用举例 以下是通过`scikit-learn`中的`K-means`类实现K-means聚类的应用举例: - 为便于理解,生成一个二分类的随机数据,将结果保存为文件“data.xlsx”: - 如果自己有数据,可以跳过这一步 ```python import numpy as np import pandas as pd # 生成数据 c1x = np.random.uniform(0.5, 1.5, (1, 100)) # 生成100个随机数 c1y = np.random.uniform(0.5, 1.5, (1, 100)) c2x = np.random.uniform(3.5, 4.5, (1, 100)) c2y = np.random.uniform(3.5, 4.5, (1, 100)) x = np.hstack((c1x, c2x)) y = np.hstack((c1y, c2y)) X = np.vstack((x, y)).T # 将数据保存为 Excel 文件 df = pd.DataFrame(X, columns=['X', 'Y']) # 创建 DataFrame,指定列名 df.to_excel('data.xlsx', index=False, engine='openpyxl') # 保存为 Excel 文件,不包含索引 ``` - 进行二分类变量K-means聚类分析 ```python import pandas as pd import matplotlib.pyplot as plt from sklearn.cluster import KMeans # 从 Excel 文件读取数据 data = pd.read_excel('data.xlsx', sheet_name='Sheet1') # 假设数据在第一个表单中 # 确认列名,假设数据列名为 'X' 和 'Y' X = data[['X', 'Y']].values # 使用 KMeans 聚类算法进行聚类 kmeans = KMeans(n_clusters=2) # 创建 KMeans 聚类器,设置聚类数为2 result = kmeans.fit_predict(X) # 训练模型并预测每个样本的簇标签 # 打印分类结果 print("Cluster labels:") print(result) # 绘制散点图展示聚类结果 plt.rcParams['font.family'] = ['sans-serif'] plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文显示 # 提取每个点的 x 和 y 坐标 x_values = X[:, 0] y_values = X[:, 1] # 绘制散点图,根据聚类结果着色 plt.scatter(x_values, y_values, c=result, marker='o') plt.xlabel('X') plt.ylabel('Y') plt.title('KMeans Clustering') plt.show() ``` - 输出结果如下图所示 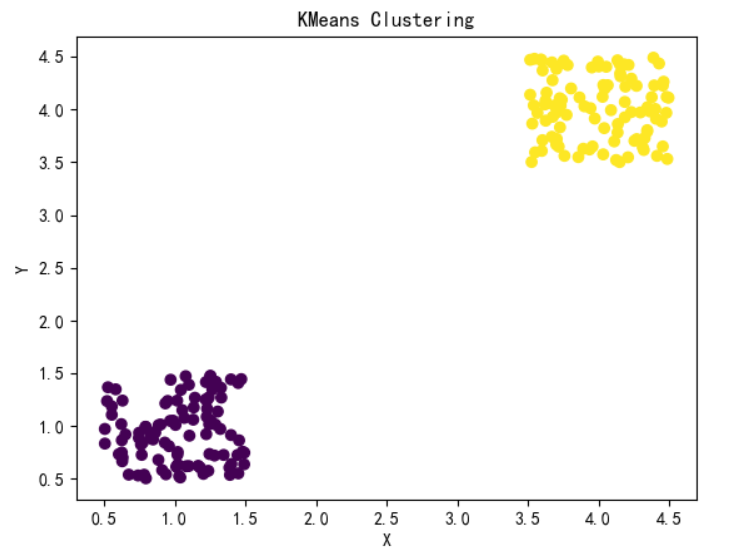 ### 2.2层次聚类 - 层次聚类是一种将数据点按照相似度进行分组的方法,每个数据点首先与自己相似度最高的点组成一个组,然后这些组再按照相似度进行合并,直到所有的点都合并到一个组中。 - 层次聚类适合那些不需要预先设定聚类数目,且希望通过层次结构理解数据内在关系的情况。然而,它的计算复杂度相对较高,对大数据集不太适合。 #### 2.2.1层次聚类逻辑步骤 - 层次聚类包括凝聚式和分裂式两种方法,通过计算相似度并采用不同的聚合策略,最终形成可视化的聚类树,有助于理解数据的层次结构和关系。 - 凝聚式:从单个数据点开始,将距离最近的两个点归为一类,逐步合并相似的簇,形成层次结构; - 分裂式:整体开始逐步分裂簇,将距离最远的两个点划分为两类,直到每个数据点形成单独的簇。 #### 2.2.2层次聚类的工具 - 层次聚类在主流的数据科学和机器学习工具中普遍有支持,以下是一些常用的工具和库: - scikit-learn:Python中一个广泛使用的机器学习库,提供了sklearn.cluster.AgglomerativeClustering类来实现凝聚式层次聚类。 - SciPy:Python科学计算库中包含了scipy.cluster.hierarchy模块,提供了丰富的层次聚类功能,如linkage函数用于计算聚类树。 - R语言中的stats包:R语言中的stats包提供了hclust函数,用于进行层次聚类分析,支持不同的距离度量和链接方式。 - MATLAB:MATLAB的Statistics and Machine Learning Toolbox中包含了linkage和cluster函数,可以进行层次聚类分析。 - Weka:Weka是一个流行的数据挖掘工具,提供了GUI和Java API,支持多种聚类算法包括层次聚类。 - Orange:Orange是一个数据挖掘和可视化工具,支持层次聚类和其他聚类算法的应用。 #### 2.2.3层次聚类应用举例 以下是通过scikit-learn进行层次聚类的应用举例: - 生成一个综合分类的数据集 ```python import numpy as np from sklearn.datasets import make_blobs from matplotlib import pyplot as plt # 生成包含4个簇的合成数据集,每个簇的中心分别位于[-1,-1], [0,0], [1,1], [2,2] # 每个簇的标准差分别为0.4, 0.3, 0.4, 0.2 # 设置随机种子确保结果的可重复性 X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [0, 0], [1, 1], [2, 2]], cluster_std=[0.4, 0.3, 0.4, 0.2], random_state=9) # 数据可视化,绘制散点图展示生成的数据分布情况 plt.scatter(X[:, 0], X[:, 1], marker='o') plt.show() ``` - 通过sklearn中的AgglomerativeClustering类进行层次聚类: ```python import pandas as pd import numpy as np from sklearn.cluster import AgglomerativeClustering from sklearn import metrics from matplotlib import pyplot as plt # 从 Excel 文件读取数据 data = pd.read_excel('data1.xlsx') # 提取特征向量 X,假设 Excel 中的列名为 'x' 和 'y' X = data[['x', 'y']].values # 定义不同的链接方法 linkage_methods = ["average", "complete", "ward"] # 遍历不同的链接方法 for method in linkage_methods: # 使用 AgglomerativeClustering 进行聚类,指定链接方法 model = AgglomerativeClustering(n_clusters=4, linkage=method) model.fit(X) # 计算 Silhouette Coefficient silhouette_score = metrics.silhouette_score(X, model.labels_, metric='euclidean') print("%s Linkage Method Silhouette Coefficient: %0.3f" % (method, silhouette_score)) # 绘制聚类结果的散点图 plt.figure() plt.axes([0, 0, 1, 1]) for l, c in zip(np.arange(model.n_clusters), "rgbk"): row_ix = np.where(model.labels_ == l) plt.scatter(X[row_ix, 0], X[row_ix, 1]) plt.axis("tight") plt.axis("off") plt.suptitle("AgglomerativeClustering (linkage=%s)" % method, size=20) plt.show() ``` - 不同参数的输出结果如下: 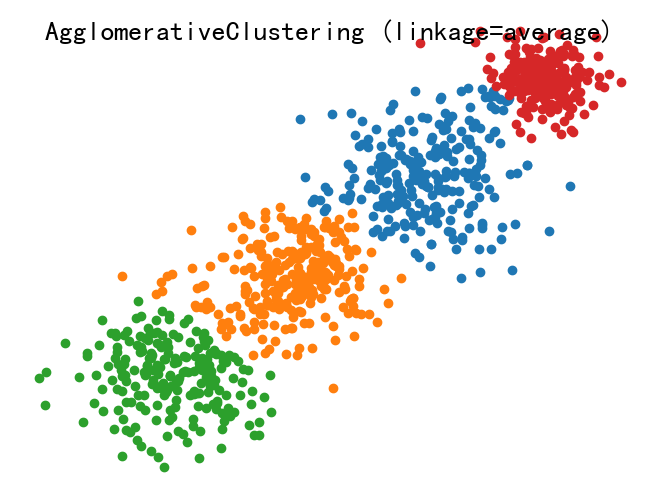 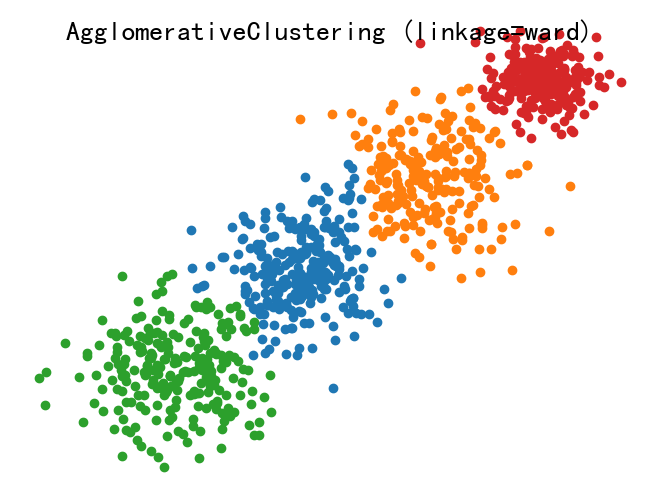 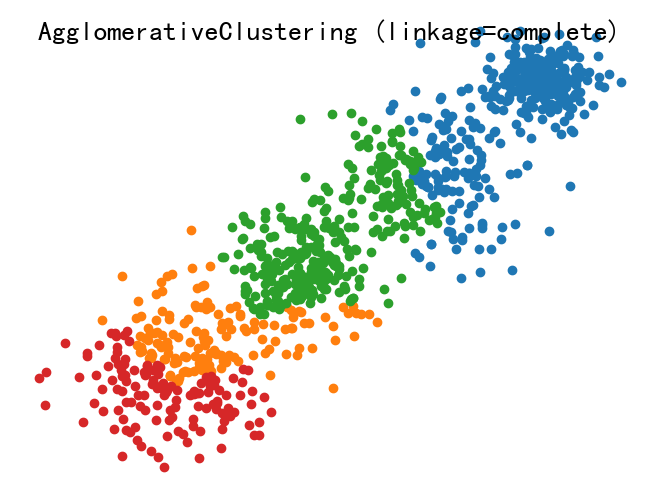 - 一般参数: - n_clusters:一个整数,指定簇的数量。 - connectivity:一个数组或者可调用对象或者为None,用于指定连接矩阵。它给出了每个样本的可连接样本。 - affinity:一个字符串或者可调用对象,用于计算距离。可以为:‘euclidean’, ‘l1’, ‘l2’, ‘manhattan’, ‘cosine’, ‘precomputed’ 。如果linkage=‘ward’,则 'affinity必须是 ‘euclidean’ 。 - memory:用于缓存输出的结果,默认为不缓存。如果给定一个字符串,则表示缓存目录的路径。 - n_components:将在scikit-learn v 0.18中移除 - compute_full_tree:通常当已经训练了n_clusters之后,训练过程就停止。但是如果compute_full_tree=True,则会继续训练从而生成一颗完整的树。 - linkage:一个字符串,用于指定链接算法。 ### 2.3DBSCAN聚类 #### 2.3.1DBSCAN聚类的核心概念 - 密度可达性:DBSCAN聚类通过计算每个数据点到其邻域内其他数据点的密度可达性,将数据点划分为不同的簇。 - 核心对象:DBSCAN聚类将数据点划分为核心对象和边界对象,核心对象是邻域内密度可达的数据点,边界对象是邻域内密度不可达的数据点。 - 噪声处理:DBSCAN聚类可以有效地处理噪声数据,将噪声数据识别为边界对象,并将其从聚类结果中剔除。 #### 2.3.2DBSCAN聚类的逻辑步骤 - 在给定的数据集中,根据每个数据点周围其他数据点的密度情况,将数据点分为核心点、边界点和噪声点。 - 核心点是周围某个半径内有足够多其他数据点的数据点; - 边界点是不满足核心点要求,但在某个核心点的半径内的数据点; - 噪声点则是不满足任何条件的点。 - 接着,从核心点开始,通过密度相连的数据点不断扩张,形成一个簇。 - 重复步骤1和步骤2,直到所有的数据点都被标记。 #### 2.3.3DBSCAN聚类应用举例 ```python import numpy as np # 导入NumPy库,用于科学计算 import matplotlib.pyplot as plt # 导入matplotlib库,用于数据可视化 from sklearn.cluster import DBSCAN # 从sklearn库中导入DBSCAN聚类算法 from sklearn.datasets import make_blobs # 从sklearn库中导入make_blobs函数,用于生成随机数据集 # 生成随机数据 X, _ = make_blobs(n_samples=100, centers=3, cluster_std=0.6, random_state=0) # make_blobs函数生成一个具有指定中心和标准差的随机数据集 # n_samples:生成的样本总数 # centers:生成的样本中心点数目 # cluster_std:每个簇的标准差,这里设置为0.6 # random_state:随机数种子,确保每次运行生成相同的随机数据 # 使用DBSCAN进行聚类分析 dbscan = DBSCAN(eps=0.5, min_samples=5) # 创建一个DBSCAN聚类器对象 # eps:DBSCAN算法参数,指定邻域的最大距离 # min_samples:DBSCAN算法参数,指定一个核心点所需的最小样本数 clusters = dbscan.fit_predict(X) # 对数据集X进行聚类,返回每个样本的簇标签 # clusters:每个样本的簇标签,-1表示噪声点 # 提取核心样本和噪声点 core_samples_mask = np.zeros_like(dbscan.labels_, dtype=bool) core_samples_mask[dbscan.core_sample_indices_] = True # np.zeros_like(dbscan.labels_, dtype=bool):创建一个与dbscan.labels_形状相同的全零数组,数据类型为布尔型 # dbscan.core_sample_indices_:DBSCAN对象的核心样本索引 # 将核心样本的索引位置设置为True,其余位置为False # core_samples_mask:布尔数组,True表示核心样本,False表示噪声点 labels = dbscan.labels_ # dbscan.labels_:每个样本的簇标签,-1表示噪声点,非负整数表示簇标签 # labels:与clusters相同,保存每个样本的簇标签 # 绘制结果 plt.figure(figsize=(8, 6)) # 创建一个8x6英寸大小的新图 # 所有点 plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis') # 绘制散点图 # X[:, 0]:所有样本的第一个特征值(x坐标) # X[:, 1]:所有样本的第二个特征值(y坐标) # c=labels:根据簇标签labels对点进行着色 # cmap='viridis':使用viridis颜色地图,用不同的颜色表示不同的簇 plt.title('DBSCAN Clustering') # 设置图的标题 plt.xlabel('Feature 1') # 设置x轴标签 plt.ylabel('Feature 2') # 设置y轴标签 plt.show() # 显示图形 ``` - 代码输出结果如下:  ## 3.补充学习,请观看下方视频: 
张龙
2024年7月18日 16:26
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码