人工智能训练师(四级)
模块0 人工智能训练师职业认知
学习单元1 人工智能概论
学习单元2 人工智能训练师岗位认知
模块1 数据采集和处理
课程1-1 业务数据采集
学习单元1 文本与图片数据采集(爬虫)
学习单元2 视频数据采集
学习单元3 语音数据采集
课程1-2 业务数据处理
学习单元1 文本数据清洗
学习单元2 图像数据清洗
模块2 原始数据标注
学习单元1 文本数据标注
学习单元2 图像数据标注
学习单元3 语音数据标注
模块3 使用Excel进行分类统计
模块4 数据归类和定义
学习单元1 聚类分析
学习单元2 回归分析
学习单元3 关联分析
模块5 标注数据审核
学习单元1 标注数据质量检验基础知识
学习单元2 图像和视频标注数据质量检验
学习单元3 语音标注数据质量检验
学习单元4 文本标注数据质量检验
模块6 智能系统运维
学习单元1 智能系统运维基础
学习单元2 系统功能日志维护
学习单元3 常见智能系统介绍
学习单元4 使用Docker进行系统安装部署
附加0 工作中常用的人工智能软件
-
+
首页
学习单元3 关联分析
## 1.关联分析 - 关联分析是数据挖掘领域中的一种技术,用于发现数据集中项目之间的关系和依赖关系。其主要目标是确定数据集中项目之间的频繁关联规则。这些规则表明,如果数据集中出现某些项目集合,则很可能出现其他项目集合。 - 关联分析是一种强大的数据挖掘技术,可以揭示数据中隐藏的模式和关系,有助于理解数据的内在结构和规律。它在商业、医学和其他领域的应用广泛,帮助决策者做出基于数据的有效决策和推荐。 ### 1.1名词解释 - 包含项与项集 - 包含项:包含项是指在关联分析中,一个项可以包含多个属性,例如“商品”项可以包含“商品名称”、“商品价格”等属性。 - 项集:项集是指在关联分析中,一组项的集合,例如{商品A, 商品B, 商品C}就是一个项集。 - 频繁项集:频繁项集是指在关联分析中,频繁出现的项集,例如{商品A, 商品B}在数据集中出现的频率很高,那么它就是一个频繁项集。 - 支持度 - 定义:支持度是指在数据集中,同时出现两个或多个项的概率。 - 计算方法:支持度可以通过计算数据集中同时出现两个或多个项的记录数,然后除以数据集的总记录数来计算。具体方程如下: 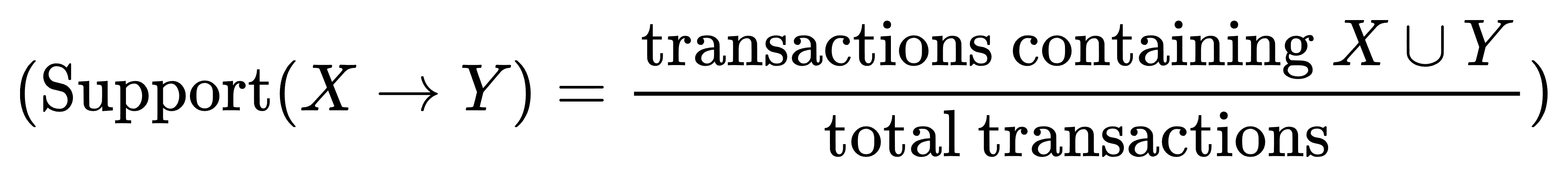 - 应用:支持度是关联分析中的重要概念,可以用来衡量两个或多个项之间的关联程度。 - 置信度 - 定义:置信度是衡量关联规则可靠性的指标,表示在给定条件下,规则成立的概率。 - 计算方法:置信度可以通过公式P(A|B) = P(A ∩ B) / P(B)来计算,其中P(A|B)表示在B发生的条件下,A发生的概率。具体方程如下: 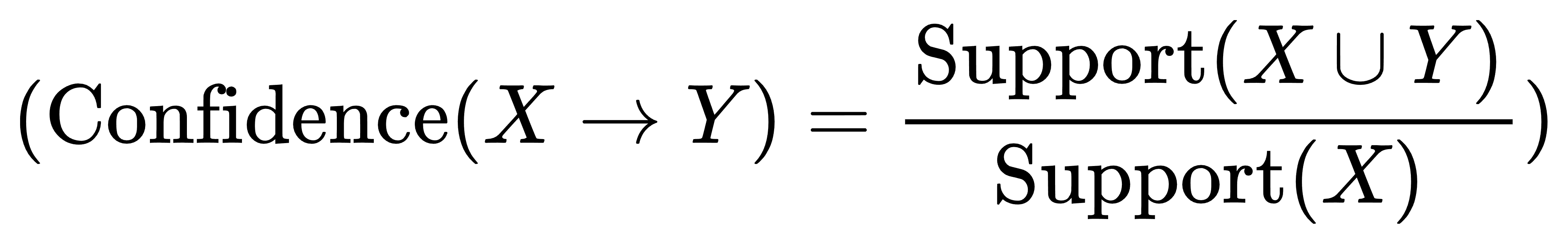 - 应用:在关联分析中,置信度越高,表示规则越可靠,可以更有效地用于预测和决策。 - 提升度 - 定义:提升度是衡量两个或多个项目之间关联程度的指标,用于判断项目之间的关联性。 - 计算方法:提升度的计算方法是将两个或多个项目的支持度相乘,再除以每个项目的支持度。具体方程如下: 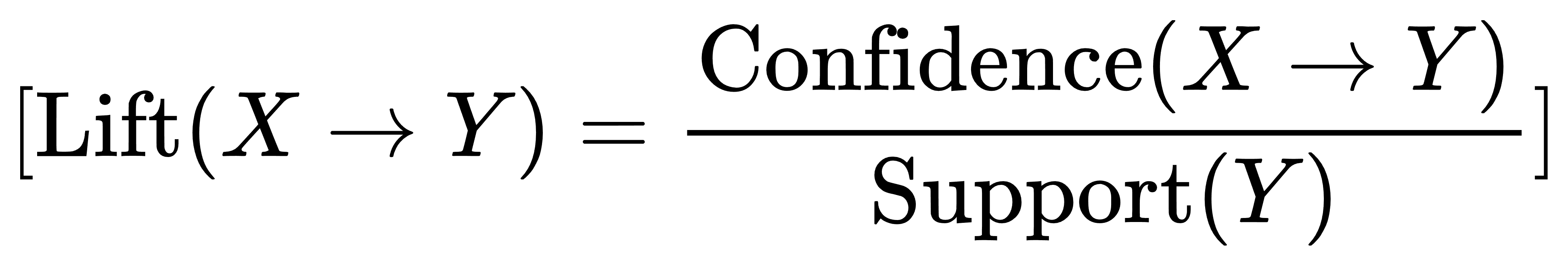 - 应用:提升度在关联分析中用于发现项目之间的关联规则,为决策提供依据。 ### 1.2关联规则挖掘的定义 - 关联规则挖掘的概念:关联规则挖掘是一种从大量数据中发现项集之间关联关系的方法。 - 关联规则的形式:关联规则通常表示为“如果-那么”的形式,如“如果购买了A商品,那么很可能也会购买B商品”。 - 关联规则的应用:关联规则挖掘在推荐系统、市场分析等领域有着广泛的应用。 ## 2.Apriori算法 Apriori算法是用于挖掘频繁项集和关联规则的经典算法,它是关联分析中最早也是最为经典的方法之一。Apriori算法的核心思想是基于先验知识(Apriori原则),通过迭代和剪枝的方式,逐层扫描数据集,从而找到频繁项集。 ### 2.1Apriori算法的基本思想 - 频繁项集:Apriori算法的基本思想是通过计算频繁项集来找出数据中的关联关系。 - 支持度:Apriori算法使用支持度来衡量一个项集在数据集中出现的频率。 - 置信度:Apriori算法使用置信度来衡量一个项集在数据集中出现的置信程度。 ### 2.2Apriori算法的步骤 - 扫描数据库,生成==候选项集==:首先扫描数据集,统计每个单个项(`item`)的支持度(出现的频率)。基于==最小支持度阈值==(`min_support`),生成频繁项集(即==支持度不低于阈值的项集==)。 - 迭代生成频繁项集 - 根据频繁k-1项集(即长度为k-1的频繁项集)生成候选k项集。具体做法是连接步骤(join step):将频繁k-1项集两两连接生成候选k项集,然后通过剪枝步骤(prune step)去除不满足最小支持度要求的候选项集,得到频繁k项集。 - 重复以上步骤,直到不能再生成新的频繁项集为止。此时,所有满足支持度要求的频繁项集都被找出来了。 - 生成关联规则:对于每个频繁项集,生成其所有可能的关联规则,并计算这些规则的置信度。根据设定的==最小置信度阈值==,过滤掉置信度低于阈值的规则,得到最终的关联规则。 - 评估关联规则:评估生成的关联规则的置信度和提升度,以确定其有效性。 ### 2.3Apriori算法的优化 - 减少扫描次数:通过减少扫描次数,提高Apriori算法的效率,降低计算复杂度。 - 并行计算:利用并行计算技术,将Apriori算法分解为多个子任务,提高计算速度。 - 改进算法:通过改进Apriori算法,如使用FP-tree等数据结构,提高算法的效率和准确性。 ## 3.关联分析与Apriori算法的应用 - 在市场篮子分析中的应用 - 识别关联商品:通过Apriori算法,可以识别出顾客在购买商品时经常一起购买的商品组合,从而帮助商家制定更有效的营销策略。 - 优化商品陈列:根据Apriori算法得出的关联商品组合,商家可以优化商品陈列,将关联商品摆放在一起,提高商品的销售量。 - 预测商品需求:Apriori算法可以帮助商家预测商品的需求量,从而提前做好库存准备,避免缺货或库存积压的情况发生。 - 在推荐系统中的应用 - 推荐商品:Apriori算法通过分析用户的购买历史,找出商品之间的关联关系,从而推荐用户可能感兴趣的商品。 - 推荐电影:Apriori算法通过分析用户的观看历史,找出电影之间的关联关系,从而推荐用户可能感兴趣的电影。 - 推荐音乐:Apriori算法通过分析用户的听歌历史,找出音乐之间的关联关系,从而推荐用户可能感兴趣的音乐。 - 在其他领域的应用 - 零售行业:Apriori算法可以帮助零售商分析顾客的购买行为,发现商品之间的关联关系,从而优化商品陈列和促销策略。 - 金融行业:Apriori算法可以用于分析客户的投资行为,发现金融产品的关联关系,为投资决策提供支持。 - 医疗行业:Apriori算法可以用于分析患者的病历数据,发现疾病之间的关联关系,为疾病诊断和治疗提供参考。 ## 4.Apriori算法python应用举例: ```python import numpy as np import pandas as pd from mlxtend.frequent_patterns import apriori, association_rules # 导入必要的库 # numpy用于生成随机数据 # pandas用于数据处理和操作 # mlxtend中的apriori和association_rules用于频繁项集挖掘和关联规则分析 # 生成随机数据集 np.random.seed(0) # 设置随机种子,确保每次运行生成的随机数据一致 data = np.random.randint(0, 2, size=(10, 5)) # 生成一个10行5列的随机二进制数据集 df = pd.DataFrame(data, columns=['A', 'B', 'C', 'D', 'E']) # 创建一个DataFrame对象,将随机生成的数据存储在其中,列名分别为'A', 'B', 'C', 'D', 'E' print("随机生成的数据集:") print(df) # 打印随机生成的数据集,展示生成的DataFrame # 使用Apriori算法挖掘频繁项集 frequent_itemsets = apriori(df, min_support=0.2, use_colnames=True) # 调用mlxtend中的apriori函数,传入数据集df、支持度阈值min_support=0.2和use_colnames=True参数 # min_support表示项集出现的频率阈值,use_colnames=True表示结果中使用列名而不是列索引来表示项集 print("\n频繁项集:") print(frequent_itemsets) # 打印找到的频繁项集,显示项集及其支持度 # 生成关联规则 rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7) # 调用mlxtend中的association_rules函数,传入频繁项集frequent_itemsets、置信度阈值min_threshold=0.7和metric="confidence"参数 # metric="confidence"表示使用置信度作为衡量关联规则质量的指标 print("\n关联规则:") print(rules) # 打印生成的关联规则,包括规则的前件、后件、支持度、置信度等信息 ``` 代码输出结果如下:   这份数据展示了使用Apriori算法进行频繁项集挖掘后的结果。每一行数据包含一个项集及其支持度,支持度表示这个项集在数据集中出现的频率。 - 支持度列:这一列显示了每个项集的支持度值。支持度是指包含该项集的交易数量占总交易数量的比例。例如,项集 {A} 的支持度为0.6,表示有60%的交易包含项 A。 - 项集列:这一列列出了具体的项集,项集用大括号 {} 括起来,表示这些项一起出现在交易中。 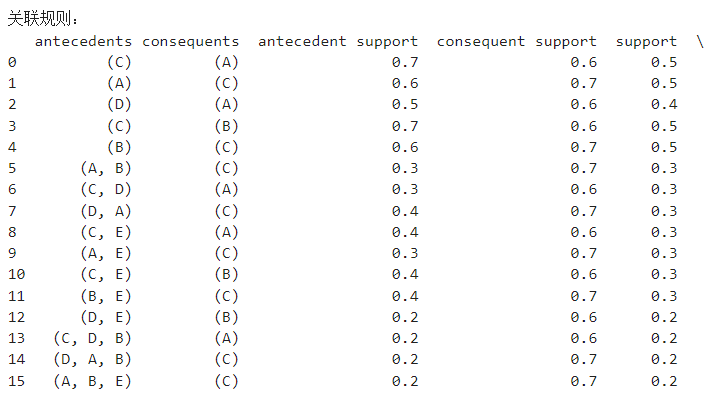 这份关联规则数据展示了一些具体的关联规则及其支持度等信息。例如: - 规则 {C} -> {A}: 支持度:0.5 置信度:支持度({C, A}) / 支持度({C}) = 0.5 / 0.7 ≈ 0.71 这条规则意味着如果一个交易中包含 C,那么它也很可能包含 A,支持度为 0.5 表示这种情况相对频繁。 - 规则 {A} -> {C}: 支持度:0.5 置信度:支持度({A, C}) / 支持度({A}) = 0.5 / 0.6 ≈ 0.83 这条规则表明如果一个交易中包含 A,那么它也很可能包含 C,支持度和置信度都比较高。 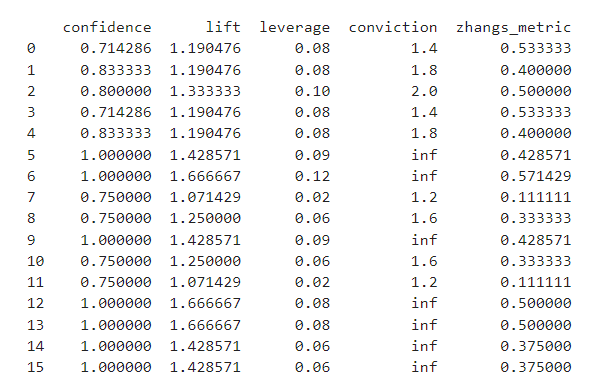 - Confidence(置信度):置信度指示了如果规则的前提发生,那么结论也会发生的频率。例如,第一个规则的置信度为 0.714286 表示,如果购买了 C,那么也有 71.43% 的可能性购买 A。 - Lift(提升度):提升度表示了规则的结论部分的事件的发生概率相对于其在两个事件独立时的发生概率的倍数。例如,提升度为 1.190476 表示,购买了 C 时,购买 A 的概率是两者独立时的 1.190476 倍。 - Leverage(支持度差):支持度差是规则的支持度与预期支持度之间的差异,预期支持度是基于假设两个事件是独立的情况下计算的。例如,第一个规则的支持度差为 0.08,表示实际支持度比预期支持度高 0.08。 - Conviction(确信度):确信度测量了规则的结论部分的事件与其条件部分独立性的程度。如果 Conviction 的值接近 1,表示条件部分和结论部分几乎独立,大于 1 表示它们之间的关联性更强。 ## 5.关联分析与Apriori算法的评估与优化 ### 5.1评估指标 - 支持度:支持度是衡量一个项集在数据集中出现频率的指标,通常用于评估关联规则的强度。 - 置信度:置信度是衡量一个关联规则在数据集中成立的可能性的指标,通常用于评估关联规则的可靠性。 - 提升度:提升度是衡量一个关联规则对目标项的影响程度的指标,通常用于评估关联规则的有效性。 ### 5.2优化策略 - 数据预处理:对数据进行清洗和预处理,去除噪声和异常值,以提高Apriori算法的准确性和效率。 - 参数调整:调整Apriori算法的参数,如支持度、置信度和最小项集大小等,以找到最佳的参数组合。 - 集成学习:将Apriori算法与其他算法相结合,如决策树、随机森林等,以提高算法的泛化能力和预测性能。 ## 6.补充学习,请观看下方视频: 
张龙
2024年7月18日 16:19
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码