数据技术应用概论
第一章 绪论
数据素质培养意义
数据技术
数据科学应用体系框架
第二章 计算机信息系统
计算机信息系统的构成
计算机信息系统技术路线
第三章 抽样技术
抽样技术概述
网络调查和社会调查
抽样学习
抽样技术的基本概念
第四章 网络爬虫与文本数据生成
网络爬虫概述
网络爬虫技术操作
文本数据生成
第五章 数据库技术
数据库技术概述
数据库系统开发
关系数据库
数据仓库
第六章 SQL语言
SQL概述
SQL关系定义
SQL查询基本结构
数据库修改
视图
第七章 数据预处理技术
数据预处理概述
数据清理
数据集成
数据规约
数据变换
第八章 回归模型
回归模型的基础知识
最小二乘法
其他常用回归模型
第九章 Logistic建模技术
基础知识
梯度上升算法
第十章 关联规则挖掘
关联规则挖掘的基础知识
关联规则挖掘的 Apriori 算法
其它常用关联规则挖掘算法
第十一章 决策树分类规则
决策树分类规则的基础知识
决策树分类规则挖掘的ID3算法
几种常用的决策树
第十二章 K-平均聚类
基础知识
基于划分的K‐平均聚类算法
其他常用的聚类
第十三章 神经网络模型
神经网络模型的基础知识
误差逆传播算法
其他常用的神经网络算法
第十四章 支持向量机
支持向量机的基础知识
支持向量机的SMO算法
其他常用的支持向量机算法
第十五章 集成学习算法
集成学习算法的基础知识
随机森林算法
其他常用的集成学习算法
第十六章 数据可视化
数据可视化的基础知识
可视化设计基础
数据可视化工具
-
+
首页
回归模型的基础知识
## 1问题提出 `回归模型能够描述响应变量(或称因变量)和一个解释变量(或称自变量)之间的关系,也能描述响应变量和多个解释变量之间的关系,比较不同衡量尺度的变量之间的相互影响,帮助研究者、数据分析人员更深入分析变量之间联系。` - 考虑种河北春小麦的某户收入: > 变量:某户收入(元)、土地(亩) 关系:某户收入 = 1500元/亩\*10亩 = 15000元 河北春小麦亩产量设定为1000斤(一般在800斤到1300斤之间,地域块、气候影响小麦产量) 小麦价格设定为1.50元/斤(1.55—1.60元/斤的小麦也不少) 小麦每亩收入:1000斤\*1.50元/斤=1500元 - 考虑种河北春小麦的某户收入: >变量:某户收入(元)、土地(亩) 关系:某户收入 = ? *10亩 = ?元 河北春小麦亩产量一般在800斤到1300斤之间 小麦价格在1.55—1.60元/斤 小麦每亩收入最低:1.55元/斤 * 800斤 =1240元 最高:1.60元/斤 * 1300斤=2080元 户收入最低:1240元/亩 * 10亩 =12400元 最高: 2080元/亩*10亩 =20800元 - 一斤桃多少元? >中国果品流通协会 2022-05-30 17:00 发表于北京产区资讯丨河北乐亭:鲜桃绘出乡村振兴甜蜜图景 唐山市乐亭县,是全国闻名的“中国桃乡”。截至目前,乐亭县桃树面积7.55万亩,年产鲜桃22.14万吨,产值11.28亿元,占全县果品总产值的73.6%,其中设施桃面积2.77万亩,年产量8.96万吨,产值8.96亿元。基本实现鲜桃的周年供应,“乐亭大桃”已成为当地增加农民收入、促进乡村振兴的“甜蜜”产业。 目前,新寨镇现有农民专业合作社、家庭农场、专业大户等新型农业经营主体和社会化服务组织达60余个,农户入社率达85%。年生产优质设施桃5000多万公斤,产值近10亿元,农民人均可支配收入达到2.5万元,真正让鲜桃成为助农增收的“仙桃”。 - 只考虑某户(指定)收入: >变量:某户收入(元)、小麦(亩) 、小麦每亩收入(元/亩)、设施桃(亩) 、设施桃每亩收入(元/亩)、养殖(亩) 、养殖每亩收入(元/亩)、 关系:某户收入 =小麦每亩收入\*小麦亩数 +设施桃每亩收入\*设施桃亩数 + 养殖每亩收入\*养殖亩数 `如何估算每户(平均)收入:` - 变量:收入(元)、小麦(亩)、设施桃(亩)、养殖(亩) 、 - 关系:收入 =小麦每亩收入\*小麦亩数 +设施桃每亩收入\*设施桃亩数 +养殖每亩收入\*养殖亩数 +... 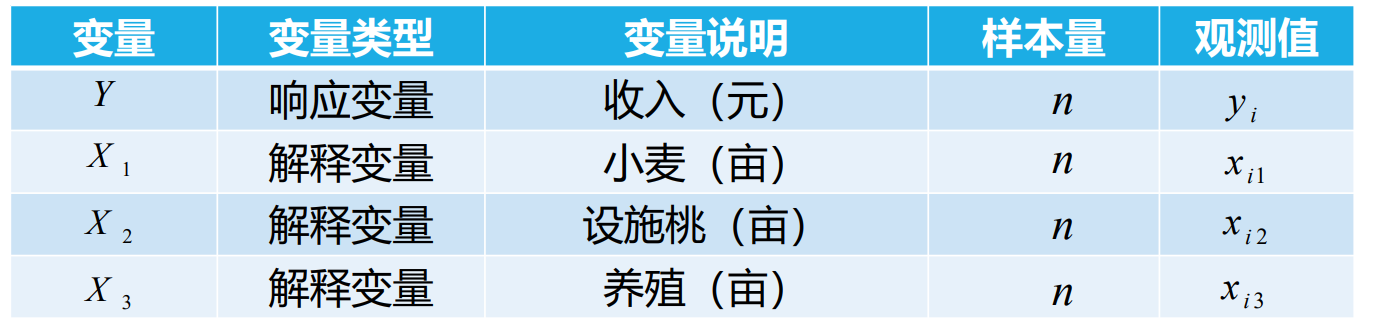 回归模型用三个解释变量$$x_1$$、$$x_2$$和$$x_3$$,描述响应变量Y的数量特征, 函数形式为: $$Y = \beta_0 +\beta_1x_1+\beta_2x_2+\beta_3x_3+\epsilon$$ 变量关系的函数形式: $$Y=\beta_0 +\beta_1x_1+\beta_2x_2+\beta_3x_3+\epsilon$$ 拟合回归模型: $$\hat Y=\hat \beta_0 +\hat \beta_1x_1+\hat \beta_2x_2+\hat \beta_3x_3$$ 每个拟合的观测值为: $$\hat y_i=\hat \beta_0 +\hat \beta_1x_i1+\hat \beta_2x_i2+\hat \beta_3x_i3,i=1,2,3....n$$ 回归模型的数据和变量符号: 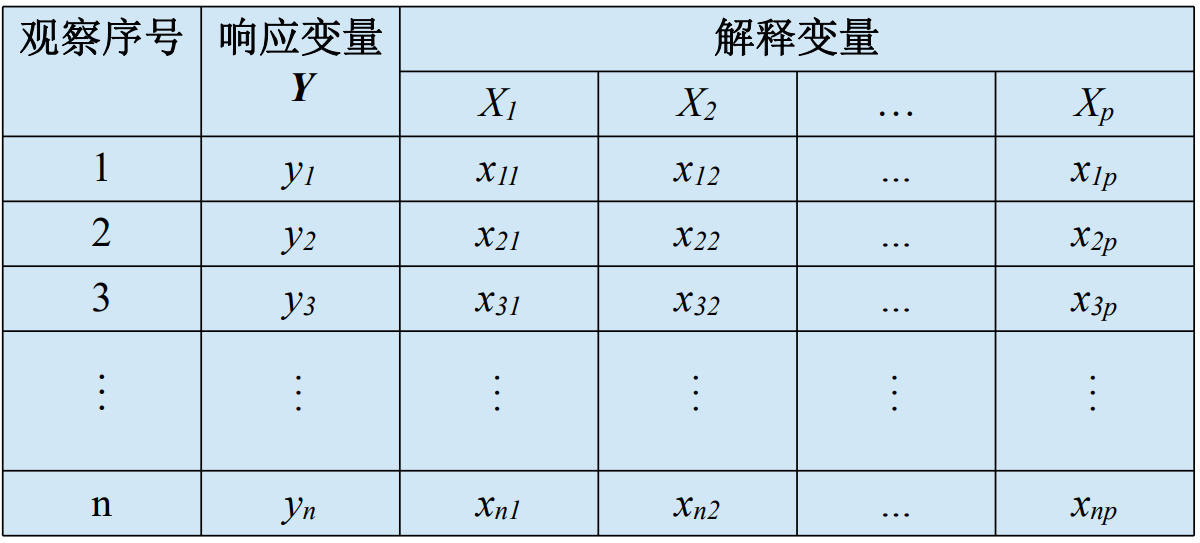 ### 引例 下表给出生育率水平数据。 响应变量Y表示生育率水平(女性人均生育数) 解释变量$$x_1$$表示人均GDP(美元)的对数 解释变量还有$$x_2$$,$$x_3$$ 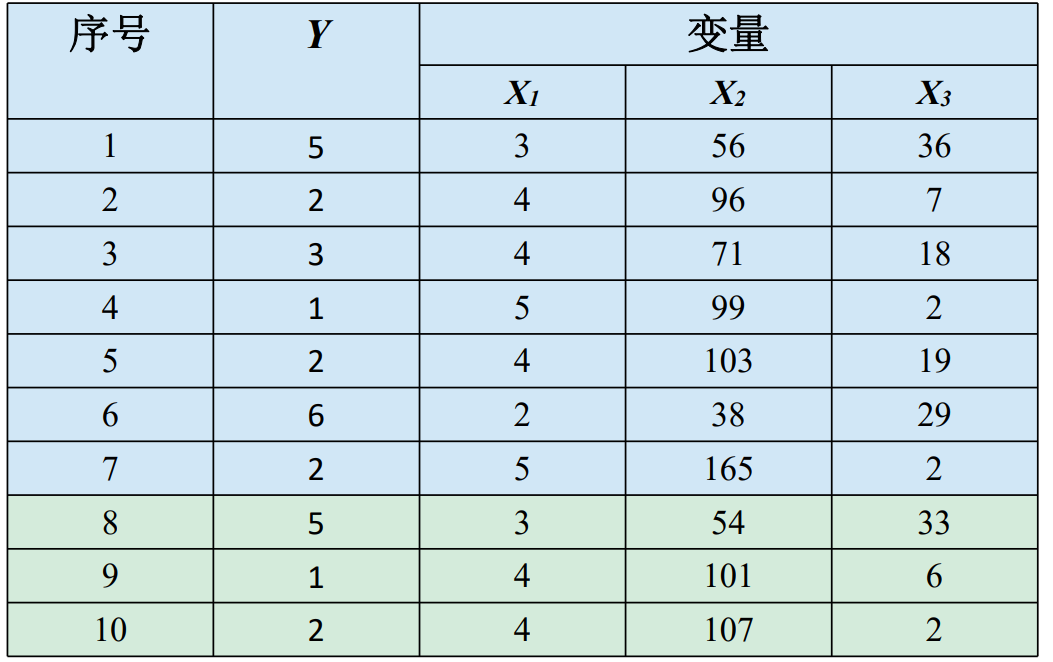 利用表中前七个观测数据,拟合模型为 $$\hat Y=\hat \beta_0 +\hat \beta_1x_i1+\hat \beta_2x_i2+\hat \beta_3x_i3$$ 可得:$$\hat \beta_0$$=7.211,$$\hat \beta_1$$1.475,$$\hat \beta_1$$=0.009,$$\hat \beta_1$$=0.040, 给出了生育率与ln(人均GDP)的拟合回归模型 $$\hat Y$$=7.211 -1.475$$x_1$$+0.009$$x_2$$+0.040$$x_3$$ - 描述生育率水平与ln(人均GDP)之间的关系。 随着ln(人均GDP)增大,生育率逐渐减小。 在其他参数给定的情况下,系数估计值为-1.475,生育率水平与ln(人均GDP)为负向关系。 在理论上GDP和生育率之间关系很复杂,与每个国家发展阶段有关。 在实际问题研究中,读者需要进一步研究样本数据特征的形成机制。 ------------ 给出了生育率与ln(人均GDP)的散点图 进一步考察生育率水平与ln(人均GDP)之间的负向关系 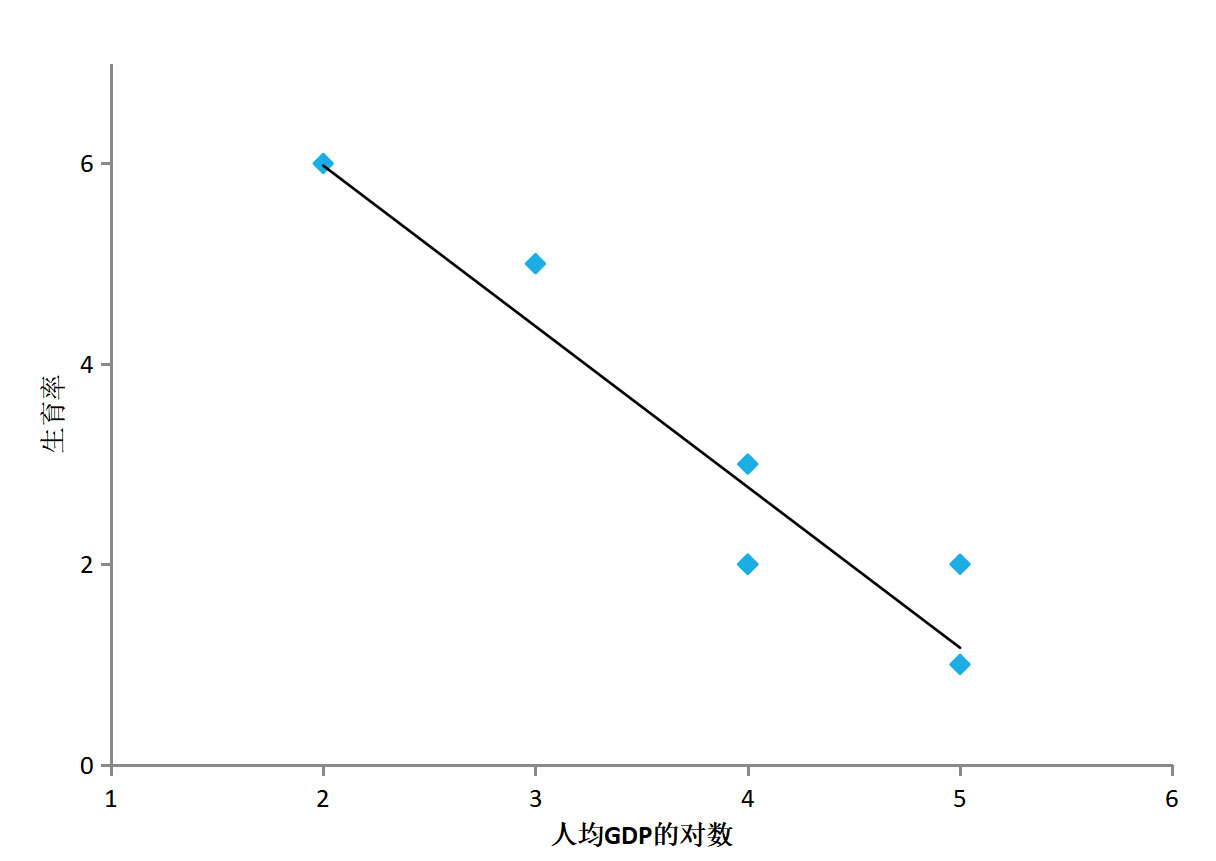 ------------ Anscombe(1973)构造了四个数据集,每个数据集有不同的构造模式,具有相同的相关系数 | 序号 | Y1 | X1 | Y2 | X2 | Y3 | X3 | Y4 | X4 | |----|-------|----|------|----|-------|----|------|----| | 1 | 8.04 | 10 | 9.14 | 10 | 7.46 | 10 | 6.58 | 8 | | 2 | 6.95 | 8 | 8.14 | 8 | 6.77 | 8 | 5.76 | 8 | | 3 | 7.58 | 13 | 8.74 | 13 | 12.74 | 13 | 7.71 | 8 | | 4 | 8.81 | 9 | 8.77 | 9 | 7.11 | 9 | 8.84 | 8 | | 5 | 8.33 | 11 | 9.26 | 11 | 7.81 | 11 | 8.47 | 8 | | 6 | 9.96 | 14 | 8.1 | 14 | 8.84 | 14 | 7.04 | 8 | | 7 | 7.24 | 6 | 6.13 | 6 | 6.08 | 6 | 5.25 | 8 | | 8 | 4.26 | 4 | 3.1 | 4 | 5.39 | 4 | 12.5 | 19 | | 9 | 10.84 | 12 | 9.13 | 12 | 8.15 | 12 | 5.56 | 8 | | 10 | 4.82 | 7 | 7.26 | 7 | 6.42 | 7 | 7.91 | 8 | | 11 | 5.68 | 5 | 4.74 | 5 | 5.73 | 5 | 6.89 | 8 | - `回归模型已经广泛应用于经济、医学、历史、社会学等领域,发挥着越来越重要的作用。` 回归模型的发现和发展是在19世纪。其创新的思想出自高尔登,使之完善化的则是以卡尔.皮尔森为代表的一批学者。 弗朗西斯·高尔登(Francis Galton)用术语“回归”解释一个重要的遗传现象,高个子的后代平均说来也高些,但不如其亲代那么高,要向平均身高的方向“回归”一些。 埃其渥斯(Edgeworth)给出回归在数学上的表达。 卡尔·皮尔逊(Karl Pearson)给出回归的更严谨数学表达,并将这种方法大量地用于分析生物测量数据,对将这一方法推向广泛的应用领域起到极大作用。  ## 2相关概念 ### 1回归模型 简单线性回归模型仅有一个响应变量(或称因变量),考察一个响应变量与一个解释变量(或称自变量)的模型,称为`一元回归模型`。实际应用常常涉及多个解释变量。若只考察某一个响应变量与多个解释变量的关系,称为`多元回归模型`。若同时考察多个响应变量与多个解释变量的关系,称为`多因变量多元回归模型`。用Y表示响应变量,用$$x_1,x_2,....x_n$$表示解释变量,p是解释变量的个数。Y和$$x_1,x_2,....x_n$$之间关系的回归模型。 $$Y=f(x_1,x_2,....x_p)+\epsilon$$ 其中$$\epsilon$$是随机误差,代表模型$$f(x_1,x_2,....x_p)$$近似真实值Y的误差,是模型不能拟合的部分。函数$$f(x_1,x_2,....x_p)$$刻画了Y和$$x_1,x_2,....x_p$$之间的关系,最常用的是`线性回归模型`: 。其中 称为回归系数, 称为截距项或常数项,其都是未知的,称为回归参数。 ### 2估计算法 当得到观测数据后,就可以对参数进行训练学习。常用的训练学习算法是`最小二乘法`。 图8.2是残差图,带箭头线段标注了回归直线上的拟合值与实际观测值的残差。基于线性回归模型 $$Y=\beta_0 +\beta_1x_1+\beta_2x_2+....\beta_px_p$$ 误差$$\epsilon$$可写为 $$\epsilon=y_i-(\beta_0 +\beta_1x_i1+\beta_2x_i2+\beta_3x_i3)$$ 其中i=1,2......n,$$x_i1,x_i2....x_ip$$,表示第i次观测时p个解释变量的观测值。 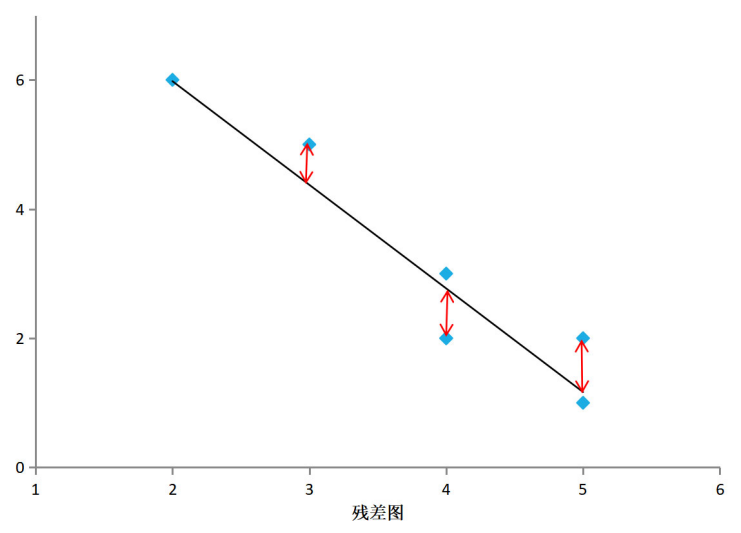 其中由误差$$\epsilon$$的表达式 $$\epsilon=y_i-(\beta_0 +\beta_1x_i1+\beta_2x_i2+\beta_3x_i3)$$ 可知误差平方和为 $$S(\beta_0,\beta_1,...\beta_p) = \sum_{i=1}^{n}\epsilon_i^2=\sum_{i=1}^{n}(y_i-\beta_0 -\beta_1x_i1-\beta_2x_i2-\beta_3x_i3)^2$$ 最小化误差$$S(\beta_0,\beta_1,...\beta_p)$$平方和的参数值为回归参数的最小二乘解,记为$$\hat \beta_0,\hat \beta_1..\hat \beta_p$$。其中,$$\hat \beta_0$$是截距项的估计,$$\hat \beta_j$$是解释变量$$x_j$$的回归系数估计 由最小二乘解得到的拟合回归模型为: $$\hat Y=\hat \beta_0 +\hat \beta_1x_1+\hat \beta_2x_2+....\hat \beta_px_p$$ 可以计算每个观测的拟合值: $$\hat y_i=\hat \beta_0 +\hat \beta_1x_i1+\hat \beta_2x_i2+....\hat \beta_px_ip$$,i=1,2,....n  得到拟合回归方程后,可以预测响应变量的平均值。例如,假设一元回归模型的拟合模型为: $$\hat Y=\hat \beta_0 +\hat \beta_1x_1$$ 解释变量值为$$x_0$$,响应变量的平均值为$$\mu_0$$,其预测值$$\hat \mu_0$$为: $$\hat \mu_0=\hat \beta_0 +\hat \beta_1x_0$$ 标准误差为: $$se(\hat \mu_0)=\sqrt{SSE/n-2}\sqrt{1/n+(x_0-\overline x_1)/\sum_{i=1}^{n}(x_i1-\overline x1)^2}$$ 统计上,给出估计值或预测值的同时要给出其误差估计
张龙
2024年8月14日 17:11
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码