数据技术应用概论
第一章 绪论
数据素质培养意义
数据技术
数据科学应用体系框架
第二章 计算机信息系统
计算机信息系统的构成
计算机信息系统技术路线
第三章 抽样技术
抽样技术概述
网络调查和社会调查
抽样学习
抽样技术的基本概念
第四章 网络爬虫与文本数据生成
网络爬虫概述
网络爬虫技术操作
文本数据生成
第五章 数据库技术
数据库技术概述
数据库系统开发
关系数据库
数据仓库
第六章 SQL语言
SQL概述
SQL关系定义
SQL查询基本结构
数据库修改
视图
第七章 数据预处理技术
数据预处理概述
数据清理
数据集成
数据规约
数据变换
第八章 回归模型
回归模型的基础知识
最小二乘法
其他常用回归模型
第九章 Logistic建模技术
基础知识
梯度上升算法
第十章 关联规则挖掘
关联规则挖掘的基础知识
关联规则挖掘的 Apriori 算法
其它常用关联规则挖掘算法
第十一章 决策树分类规则
决策树分类规则的基础知识
决策树分类规则挖掘的ID3算法
几种常用的决策树
第十二章 K-平均聚类
基础知识
基于划分的K‐平均聚类算法
其他常用的聚类
第十三章 神经网络模型
神经网络模型的基础知识
误差逆传播算法
其他常用的神经网络算法
第十四章 支持向量机
支持向量机的基础知识
支持向量机的SMO算法
其他常用的支持向量机算法
第十五章 集成学习算法
集成学习算法的基础知识
随机森林算法
其他常用的集成学习算法
第十六章 数据可视化
数据可视化的基础知识
可视化设计基础
数据可视化工具
-
+
首页
最小二乘法
## 1.最小二乘法解读 表8.1给定的n=10组观测数据,将数据集划分为两个集合,序号1至7的观测数据构成训练集,序号8至10的观测数据为测试集。通过拟合模型的预测值与实际值的比较验证模型拟合效果,评价模型的优良性。 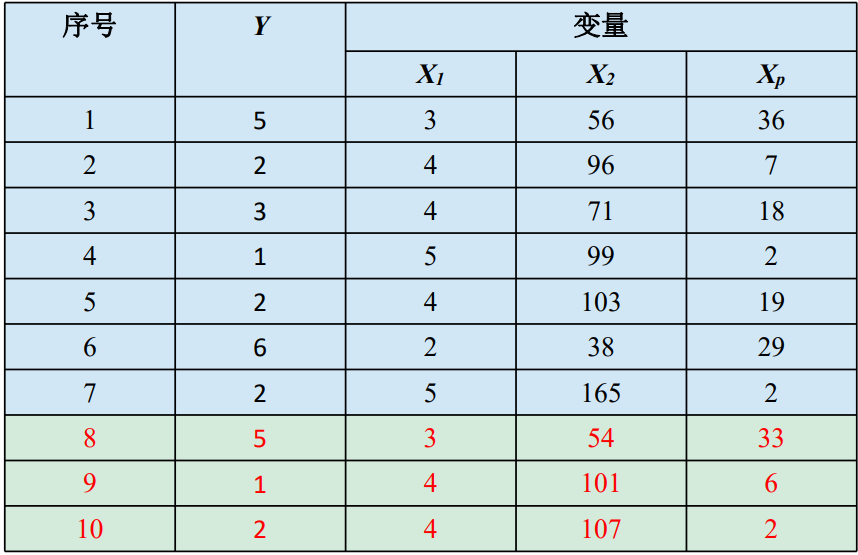 训练集的观测值满足: $$y_1=\beta_0+\beta_1x_i1+\beta_2x_i2+....\beta_px_ip+\epsilon_i$$ `最小二乘法的目标是:使得残差平方和达到最小。` 残差平方和为 $$\sum_{i=1}^{n}e_i^2=\sum_{i=1}^{n}(y_i-(\beta_0+\beta_1x_i1+\beta_2x_i2+....\beta_px_ip))^2$$ 为了方便,残差平方和用矩阵表示。X表示设计矩阵,e为残差列向量,$$\beta$$为回归系数的列表示。残差平方和的矩阵表示为:$$e'e=(y-x\beta)'(y-x\beta)$$ 残差平方和最小的条件是: $$\partial(e'e)/\partial\beta=-2x'y+2x'x\beta=0$$ 即: $$\hat \beta=(x'x)^{-1}x'y$$ ------------  引例数据为上表前六行 ### 最小二乘法的算法步骤 #### 1.计算行列式 判断矩阵$$x'x$$满秩,矩阵行列式$$|x'x|$$=35025704,不为零,说明矩阵满秩 #### 2.求$$x'x$$的逆矩阵 将扩展矩阵$$[x'x I]$$,经过初等变换,变形为$$[I (x'x)^{-1}]$$的矩阵、 #### 3.计算回归系数 将$$(x'x)^{-1}.x'.y$$带入最小二乘法公式中,有 $$\hat \beta =(x'x)^{-1}x'y=(7.211,-1.475,0.009,0.040)'$$ 可得到拟合模型为 $$\hat Y=7.211-1.475x_1+0.009x_2+0.040x_3$$ #### 4.模型预测的评价 选取训练集的观测数据,进行模型预测效果评价。 第8个观测的观测值为$$\hat y_8=7.211-1.475*3+0.009*54+0.04*33=4.592$$ 观测值与预测值的差值为0.408 类似的。计算第9.10个观测值与预测差值分别为1.46,0.354差值较小,从整体而言,观测值与预测值比较接近 ## 2.最小二乘法的有效性边界 在使用最小二乘法时,需要满足一些基本假定,包括模型形式假定,误差假定,观测假定 >1.模型形式假定 响应变量Y与解释变量$$X_1,X_2....X_p$$之间关系的模型关于回归参数是线性的。若线性假定不满足,有时通过数据变换,将其转变为线性的。 >2.误差假定 误差$$\epsilon_i,i=1,2.....n$$的均值均为0,方差为$$\sigma^2$$,误差相互独立 >3.观测值假定 所有观测都是同样可靠的,对回归结果的计算和对结论的影响有基本相同的作用 #### 示例代码 - 使用本平台在线工具进行学习。 - 地址:首页->工作台[【快捷链接】](https://zenodt.com/workbench "【快捷链接】"),点击 _1717661367.png) 按钮,登录即可。 ## 3.实现最小二乘法预测学生身高体重案例 ```python 1.导入依赖包 import numpy as np import matplotlib.pyplot as plt import scipy as sp from scipy.optimize import leastsq 2.导入学生升高体重数据 # 身高数据 Xi = np.array([162, 165, 159, 173, 157, 175, 161, 164, 172, 158]) # 体重数据 Yi = np.array([48, 64, 53, 66, 52, 68, 50, 52, 64, 49]) 3.根据数据选择模型函数和偏差函数 # 需要拟合的函数func()指定函数的形状 def func(p, x): k, b = p return k*x + b # 定义偏差函数,x,y为数组中对应Xi,Yi的值 def error(p, x, y): return func(p, x) - y 4.设置相关参数 # 设置k,b的初始值,可以任意设定,经过实验,发现p0的值会影响cost的值:Para[1] p0 = [1, 20] # 把error函数中除了p0以外的参数打包到args中,leastsq()为最小二乘法函数 Para = leastsq(error, p0, args=(Xi, Yi)) # 读取结果 k, b = Para[0] print('k=', k, 'b=', b) 5.绘图观察数据 # 画样本点 plt.figure(figsize=(8, 6)) plt.scatter(Xi, Yi, color='red', label='Sample data', linewidth=2) # 画拟合直线 x = np.linspace(150, 180, 80) y = k * x + b # 绘制拟合曲线 plt.plot(x, y, color='blue', label='Fitting Curve', linewidth=2) plt.legend() # 绘制图例 plt.xlabel('Height:cm', fontproperties='simHei', fontsize=12) plt.ylabel('Weight:Kg', fontproperties='simHei', fontsize=12) plt.show() ``` ```python 计算残差 #导入依赖 from statsmodels.graphics.api import qqplot # 定义变量 xy_res=[] # 定义计算残差函数 def residual(x,y): res = y - (0.4211697*x-8.2883026) # 计算残差 return res # 循环读取残差 for d in range(0,len(Xi)): res = residual(Xi[d], Yi[d]) xy_res.append(res) print(xy_res) # 计算残差平方和,和越小表明拟合的情况越好 xy_res_pingfangsum = np.dot(xy_res,xy_res) print(xy_res_pingfangsum) # 画样本点 fig = plt.figure(figsize=(8, 6)) ax = fig.add_subplot(111) # 添加一个子图 fig = qqplot(np.array(xy_res),line='q',ax=ax) # 设置参数 plt.show() ```
张龙
2024年8月12日 14:55
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码