数据技术应用概论
第一章 绪论
数据素质培养意义
数据技术
数据科学应用体系框架
第二章 计算机信息系统
计算机信息系统的构成
计算机信息系统技术路线
第三章 抽样技术
抽样技术概述
网络调查和社会调查
抽样学习
抽样技术的基本概念
第四章 网络爬虫与文本数据生成
网络爬虫概述
网络爬虫技术操作
文本数据生成
第五章 数据库技术
数据库技术概述
数据库系统开发
关系数据库
数据仓库
第六章 SQL语言
SQL概述
SQL关系定义
SQL查询基本结构
数据库修改
视图
第七章 数据预处理技术
数据预处理概述
数据清理
数据集成
数据规约
数据变换
第八章 回归模型
回归模型的基础知识
最小二乘法
其他常用回归模型
第九章 Logistic建模技术
基础知识
梯度上升算法
第十章 关联规则挖掘
关联规则挖掘的基础知识
关联规则挖掘的 Apriori 算法
其它常用关联规则挖掘算法
第十一章 决策树分类规则
决策树分类规则的基础知识
决策树分类规则挖掘的ID3算法
几种常用的决策树
第十二章 K-平均聚类
基础知识
基于划分的K‐平均聚类算法
其他常用的聚类
第十三章 神经网络模型
神经网络模型的基础知识
误差逆传播算法
其他常用的神经网络算法
第十四章 支持向量机
支持向量机的基础知识
支持向量机的SMO算法
其他常用的支持向量机算法
第十五章 集成学习算法
集成学习算法的基础知识
随机森林算法
其他常用的集成学习算法
第十六章 数据可视化
数据可视化的基础知识
可视化设计基础
数据可视化工具
-
+
首页
其他常用回归模型
## 1.最小二乘法的改进技术 `在实际应用中,最小二乘法不总是适用的` 标准化残差图: 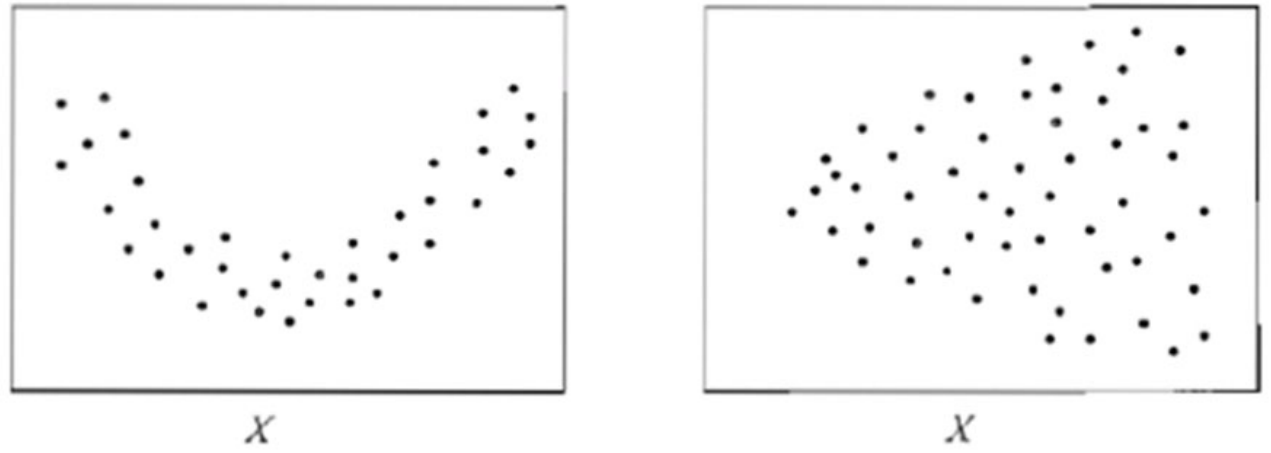 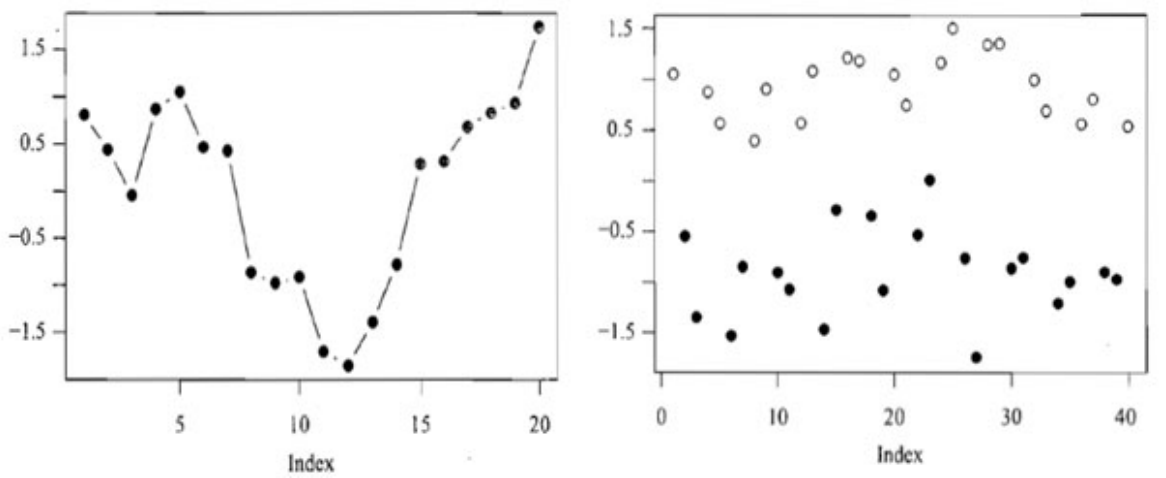 **假设违背情况下的回归模型参数估计方法** #### 1.加权最小二乘法 - `当每个观测数据的重要性不同,需要采取加权最小二乘法估计` 假定回归模型的形式为: $$y_i=\beta_0+\beta_1x_i1+\beta_2x_i2....+\beta_px_ip+\epsilon_i$$ $$\epsilon_i$$为随机误差项,当这些随机误差项同等重要性时,采用最小二乘法估计回归模型参数。权重代表重要性,有时用方差描述,有时由调查数据的决定。设权重记为 $$\omega_i,i=1,....n$$ 加权二乘法时最小化加权误差平方和, $$\sum_{i=1}^{n}wi\epsilon_i^2=\sum_{i=1}^{n}w_i(y_i-\beta_0-\beta_1x_i1-....\beta_px_ip)^2$$ 当观测值的权重都相等,即$$\omega_1=...=\omega_n$$,加权最小二乘法的估计结果即为最小二乘法的估计结果 #### 2.广义最小二乘法 - `采用最小二乘法估计模型系数时,需要条件随机误差的方差相等。当随机误差的方差不等时,常常使用广义最小二乘法。` 有时利用最小二乘估计法计算先得到残差的估计值,在最小二乘法估计参数的基础上是对参数进行加权,依据残差估计值确定权重,使之成为一个不存在异方差性的模型,再采用加权最小二乘法估计其参数。 加权最小二乘估计是广义最小二乘法的特殊情况,加权最小二乘估计法中的权重矩阵是对角阵。 假定回归模型的形式为:$$Y=X\beta+\epsilon,\epsilon=(\epsilon_1,\epsilon_2..\epsilon_n)$$为残差列向量,X为设计矩阵,$$\beta$$为回归系数列。且 $$Var(\epsilon)=\sigma^2\sum$$ 令$$M=\sum_{}^{-0.5}$$,于是 $$MY=MX\beta+M\epsilon$$ $$\widetilde Y=\widetilde X\beta +\widetilde \epsilon$$ 其中$$Var(\widetilde \epsilon)=\sigma^2I_n$$ ## 2.几类常用回归模型 ### 1.异方差模型(heteroscedastic models) - `异方差模型是指模型误差方差不等的回归模型`。在前文中,假定误差$$\epsilon$$的方差$$\sigma^2$$相等,并采用最小二乘法估计回归系数。然而,当误差方差不等时,常采用加权最小二乘法 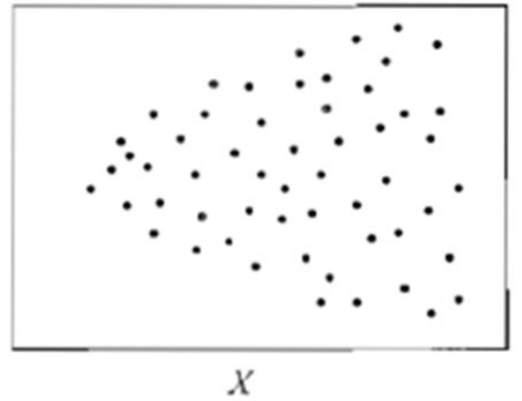 ### 2.广义线性模型 - `广义线性模型适用于有界的或离散的响应变量。` (1)对变化范围较大且取值为正的变量建模,例如:价格或者人口等。使用偏态分布如对数 正态分布或泊松分布更合适。这里,线性模型不适用于对数正态数据建模,而是对响应变量进行对 数正态的简单变化。这种情况下的回归分析往往称为泊松回归。 (2)对分类数据建模,例如:性别变量男女。使用二元选择的伯努利分布和二项分布,或者 多元选择的分类分布和多项分布更合适。常用的模型是Logistic 回归和Probit回归,以及多项 Logistic回归和多项Probit回归。 (3)对有序变量建模,例如对商品的评价等级:从0到5。不同的等级是有序的,但是等级表 示并没有绝对的意义。等级为4的商品并不表示比等级为2的商品好两倍,仅仅表示前者比后者好。此时常用的是有序Probit回归模型。 - 广义线性模型的结构分为三个部分,分别是随机部分、系统部分和联系函数。 >1.随机部分:多数情况下,响应变量Y的观测值$$Y_1,Y_2....Y_n$$之间是相互独立的,对应假设采用正态分布。在实际应用中,响应变量的观测值的分布依赖于所研究的具体问题。二分类响应变量对应假设采用二项分布。响应变量为成功次数,对应假定采用二项分布。响应变量为计数的,对应假定采用泊松分布或负二项分布。这些对应假设是基于经验的结果。在很多情况下,都能得到较好的拟合模型。 >2.系统部分:指解释变量及其进入模型的函数形式。解释变量组合$$\beta_0+\beta_1x_1+....\beta_px_p$$指解释变量的主效应作为可加效应引入到模型中。也可以将交互效应或二次效应引入模型。 >3.联系函数:指响应变量的期望与解释变量的效应组合联系起来的函数。可以是线性函数,也可以非线性函数。常用的联系函数有恒等联系、对数联系、对数优势联系。记$$E(Y)=g(\mu)=\mu$$为恒等联系,则$$g(\mu)=\beta_0+\beta_1x_1+....\beta_px_x$$ ### 3.分层线性模型 - 分层线性模型(hierarchical linear model)[或多层回归模型(multilevel regression model)]是`将数据组织成回归分层结构`。例如,A在B上回归,B在C上回归。其常用于对具有自然层次结构的变量进行建模。 例如教育统计中,学生是嵌套在学校,学校嵌套在一些行政组织,如学区,等等。响应变量可以是学生成绩的度量,例如测试分数。在学校和学区等层次中收集不同的变量作为协变量对模型加以控制。 例如: 不同学校的学生成绩可以假设相互独立。但同一班级的学生成绩由于受相同学校变量的影响,很难保证相互独立。随机误差有两部分构成,一部分是学生个体间差异,另一部分是学校的差异。传统回归模型不再适用。需要将层次特征的数据分开在每一层上,学生成绩相互独立,学校的误差在学校之间是相互独立的。 ### 4.LASSO回归模型 - LASSO(least absolute shrinkage and selection operator)方法是一种`压缩估计,主要是用来处理共线性数据`。在最小二乘法的基础上,通过惩罚函数压缩一些系数,设定其系数为零。在估计参数的同时,也实现了变量的选择。LASSO方法是一种有偏估计,给出回归系数的有偏估计量。 效应稀疏性假设:有用的信息却非常有限。回归模型的成百上千的自变量X,假设只有有限个X的回归系数不为0,但其余的都是0。 ### 5.分位数回归模型 - 分位数回归(quantile regression)模型是`利用解释变量的多个分位数(例如四分位、十分位、百分位等)得到响应变量的条件分布`,相应的分位数方程,设法使所构建的方程与样本之间的距离最短。分位数回归对总体没有正态分布的要求,放宽随机误差项的正态要求,兼顾整个分布的信息以及分位点的影响。 分位数回归既能研究在不同分位点处自变量X对于因变量Y的影响变化趋势,也能研究在不同分位点处的哪些自变量X是主要影响因素。原理是将数据按因变量进行拆分成多个分位数点,研究不同分位点情况下时的回归影响关系情况。 例如:研究学习时间对学业成绩的影响,使用分位数回归研究学习时间每增加一个单位,学生的学业成绩会如何变化。这里的学生可以是学习成绩位列前20%的学生,也可以是位列 50%的学生,还可以是位列后20%的学生。研究范围变大,可以分析群体异质性。
张龙
2024年8月12日 17:40
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码