数据技术应用概论
第一章 绪论
数据素质培养意义
数据技术
数据科学应用体系框架
第二章 计算机信息系统
计算机信息系统的构成
计算机信息系统技术路线
第三章 抽样技术
抽样技术概述
网络调查和社会调查
抽样学习
抽样技术的基本概念
第四章 网络爬虫与文本数据生成
网络爬虫概述
网络爬虫技术操作
文本数据生成
第五章 数据库技术
数据库技术概述
数据库系统开发
关系数据库
数据仓库
第六章 SQL语言
SQL概述
SQL关系定义
SQL查询基本结构
数据库修改
视图
第七章 数据预处理技术
数据预处理概述
数据清理
数据集成
数据规约
数据变换
第八章 回归模型
回归模型的基础知识
最小二乘法
其他常用回归模型
第九章 Logistic建模技术
基础知识
梯度上升算法
第十章 关联规则挖掘
关联规则挖掘的基础知识
关联规则挖掘的 Apriori 算法
其它常用关联规则挖掘算法
第十一章 决策树分类规则
决策树分类规则的基础知识
决策树分类规则挖掘的ID3算法
几种常用的决策树
第十二章 K-平均聚类
基础知识
基于划分的K‐平均聚类算法
其他常用的聚类
第十三章 神经网络模型
神经网络模型的基础知识
误差逆传播算法
其他常用的神经网络算法
第十四章 支持向量机
支持向量机的基础知识
支持向量机的SMO算法
其他常用的支持向量机算法
第十五章 集成学习算法
集成学习算法的基础知识
随机森林算法
其他常用的集成学习算法
第十六章 数据可视化
数据可视化的基础知识
可视化设计基础
数据可视化工具
-
+
首页
关联规则挖掘的 Apriori 算法
## 1.Apriori算法解读 关联规则挖掘算法大体分为两步: 首先找出所有频繁项集; 其次由频繁项集产生强关联规则。以表 10.1 的数据为例, 事先假定最小支持度 $$min_s$$=40%, 最小置信度$$mixn_c$$=70%。具体步骤如下: 1. 找出所有频繁项集 Apriori采用逐层搜索迭代的方法。即在表10.1中找出每单一商品被购买的数量, 记为候选 1-项集$$c_1$$, 具体见表10.2, 其中, 项集表示T100——T1000所有事务购买的同 一商品的集合, 支持度计数表示对应商品的购买数量。譬如表 10.2 第二列表示T100——T1000 所有事务购买{A}商品, 计数合计 5 。其余以此类推。 <br/> | 项集 | {A} | {B} | {C} | {D} | {E} | {F} | | --- | --- | --- | --- | --- | --- | --- | | 支持度计数 | 5 | 8 | 8 | 2 | 6 | 5 | <br/> ① 算法的第一次迭代。由于最小支持度为 40%, 共有T100——T1000 十条购买事务, 对应的支持度计数为 4 。则在候选 1-项集$$C_1$$中至少出现 4 次以上的项目, 才能满足最小 支持度条件, 其为对应 40% 最小支持度的频繁项集。对候选 1-项集$$C_1$$扫描, 筛选出满足最小支持度的项集,组成频繁 1-项集$$L_1$$,见表10.3。显然{A},{B},{C},{D},{E},{F}项集中,{D}因 2 的支持度计数小于 4 而被剔除 ② 进行第二次迭代。 由于频繁 1-项集$$L_1$$的事项, 不重复地两两组合, 并计算相应支持度计数, 产生由两种商品组合的候选 2-项集$$C_2$$。参见示意表10.4, 其中第二列第二行表示 {A}和{B}的组合{AB}具有 4 个支持度计数。仍然基于最小支持度 40% 的假设扫描候选 2-项集$$C_2$$。 | 项集 | {A B} | {A C} | {A E} | {A F} | {B C} | | --- | --- | --- | --- | --- | --- | | 支持度计数 | 4 | 5 | 3 | 3 | 6 | | 项集 | {B E} | {B F} | {C E} | {C F} | {E F} | | 支持度计数 | 5 | 3 | 4 | 4 | 3 | 再次篮选出满足最小支持度的项集, 由满足最小支持度的项集组成频繁 2-项集{$$L_2$$}。参 见示意表10.5。其中,{AE}.{AF}.{BF}和{EF}等 4 个项集因支持度计数小于 4 而 被剔除 | 项集 | {A B} | {A C} | {B C} | {B E} | {C E} | {C F} | | --- | --- | --- | --- | --- | --- | --- | | 支持度计数 | 4 | 5 | 6 | 5 | 4 | 4 | ③ 类似地, 由频繁 2-项集$$L_2$$, 产生三种商品组合的候选 3-项集$$C_3$$。其中, Apriori 具有压缩搜索空间的性质, 可提高频繁项集逐层产生的效率。该性质的思想很简单, 即频繁项集的所有非空子集也必须是频繁的。如果项集I不满足$$s(I)\geq min_s$$, 则I不是频繁的。如果项$$A$$添加到项集$$I$$, 则结果项集 (即$$I∪A$$) 不可能比$$I$$具有更高的支持度。 因此, $$I∪A$$ 也不是频繁的, 即$$P(I∪A)\leq min_s$$。利用 Apriori 性质对$$C_3$$中的项集进行剪枝, 即删除其中不可能是频繁的项集, 得到三个项目组合的候选 3-项集$$C_3$$。参见示意表10.6 | 项集 | {A B C} | {B C E} | | --- | --- | --- | | 支持度计数 | 4 | 4 | 同理,再次基于最小支持度40%的假设扫描候选 3-项集$$C_3$$,确定频繁 3-项集$$L_3$$。参见示意表10.7。 | 项集 | {A B C} | {B C E} | | --- | --- | --- | | 支持度计数 | 4 | 4 | ④ 由$$L_3$$可产生候选 4-项集$$C_4$$,由于本例所得到$$C_4$$子集不是频繁的, 被剪去, 所以得到$$C_4=\varnothing $$。至此本例算法终止, 找出了所有的频繁项集。 2. 由频繁项集产生强关联规则 从事务数据库$$D$$中找出频繁项集后,通过计算置信度即可找出强关联规则。由于$$min_c=70%$$,规则的置信度至少要大于70%才能形成强关联规则 ① 对于频繁 2-项集$$L_2$$中的每一个元素$$I_2$$= {$$S_1$$},{$$S_2$$},其非空子集{$$S_1,S_2$$} - 如果 $$C(S_1\Rightarrow S_2)\geq min_c$$ `则输出强关联规则 "$$S_1\Rightarrow S_2$$" 。` - 如果 $$C(S_1\Rightarrow S_2)\leq min_c$$ `则关联规则 "$$S_1\Rightarrow S_2$$" 不是强规则。 ② 对于频繁 3-项集$$L_3$$中的每一个元素$$I_2$$= {$$S_1,S_2$$}其非空子集{$$S_1$$},{$$S_2$$},{$$S_3$$} ,{$$S_1,S_2$$},{$$S_1,S_3$$},{$$S_2,S_3$$} - 如果 $$C(S_1\Rightarrow S_2,S_3)\geq min_c$$ `则输出强关联规则 “$$S_1\Rightarrow S_2,S_3$$”` 。 - 如果 $$C(S_1\Rightarrow S_2,S_3)\leq min_c$$ `则关联规则 “$$S_1\Rightarrow S_2,S_3$$” 不是强规则, 舍去。针对其他的 3-项集元素进行同样的计算,可找出所有的针对 3-项集的强规则`。 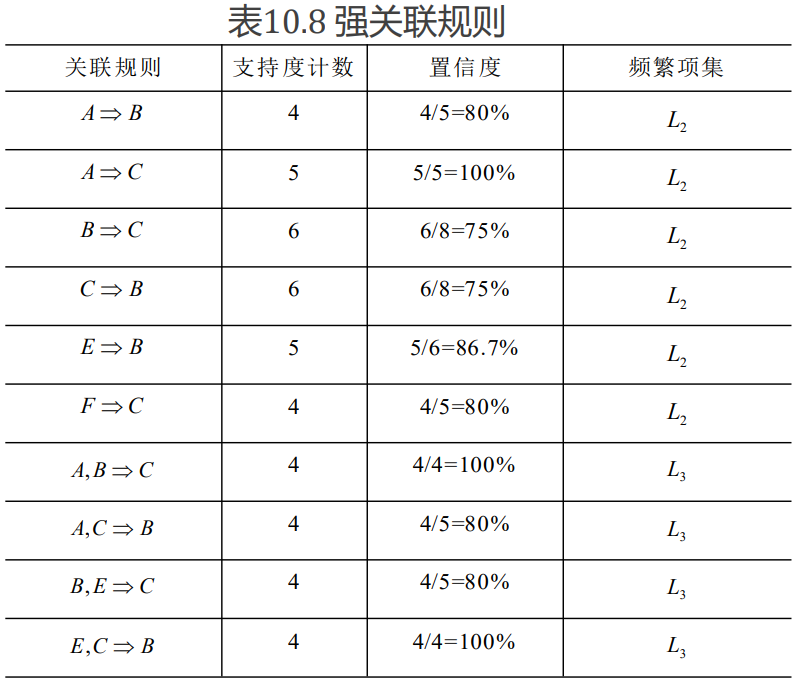 ## 2.Apriori 算法有效性边界 - ① 对数据库扫描次数过多, 造成效率低下。通过 Apriori算法的解读可知, 每 生成一个候选项集, 都要对数据库进行一次全面搜索。如果要生成最大长度为的频繁项集, 那么就要对数据库进行 N 次扫描。当数据库中存放大量事务数据时, 在有限内存容量下, 系统 I/O 负载相当大, 每次扫描数据库的时间就会很长, 其效率非常低。 - ② Apriori算法产生大量中间项集。Apriori 算法是用$$L_1$$产生候选 $$C_k$$,所产生的 $$C_k$$由$$C_{L_{k-}}^k$$个 K-项集组成。显然, k 越大所产生候选 k-项集的数量呈几何级数增加。如频繁 1-项集的数量为 104 个, 如果要生成一个更长规则, 其需要产生候选项集的数量将达到天文数字 - ③ 采用唯一支持度,缺失各属性重要程度信息。现实中,一些事务频繁发生,有些事务则很稀疏,其给数据挖掘带来一个问题:如果最小支持度阈值设定较高,虽然速度加快,但是覆盖数据较少,有意义的规则可能不被发现;如果最小支持度阈值设定过低,大量无实际意义的规则将充斥整个挖掘过程,降低挖掘效率和规则的可用性。甚至影响误导决策的制定。 - ④ 算法适应面较窄。该算法只考虑了单维布尔关联规则的挖掘,但在实际应用中,可能出现多维的、数量的、多层的关联规则。这时,该算法就不再适用,需要改进,甚至需要重新设计算法。 #### 示例代码 - 使用本平台在线工具进行学习。 - 地址:首页->工作台[【快捷链接】](https://zenodt.com/workbench "【快捷链接】"),点击 _1717661367.png) 按钮,登录即可。 ## 3.关联分析实例 ```python # 导入包 import numpy as np import pandas as pd import os for dirname, _, filenames in os.walk('/input'): for filename in filenames: print(os.path.join(dirname, filename)) # 读取数据,共有76条数据,34个属性列 fl = pd.read_csv('Information security studentsgrades from freshman to junior.csv') # 设置排名为索引 fl.set_index('排名',inplace=True) fl.head() # 检查缺失值 check_null = fl.isnull().sum() check_null # 删除有缺失值的属性列 drop_arr = ['大学英语二', '大学英语三', '大学英语四', '大学英语二.1', '大学英语三.1', '大学英语一'] fl.drop(drop_arr, axis=1, inplace=True) fl.head() # 删除不研究属性列 drop_arr = ['学号','大学语文','中国近现代史纲要','思想道德修养与法律基础','马原','毛泽东思想与中国特色社会主义理论体系概论','总分'] t = fl.drop(drop_arr, axis=1, inplace=False) t.head() # 分类统计数据类型 t.dtypes.value_counts() # 查看数据统计信息 t.describe() # 按成绩高于75的成绩算作成绩有效 seventy_5 = [75,75,75,75,75,75,75,75,75,75,75,75,75,75,75,75,75,75,75] ax = np.full_like(t,seventy_5) ax[:5] t = t > ax t.head() # 将初步预处理后的数据转化为csv # t.to_csv('grades_processed.csv',encoding='utf-8') data = pd.read_csv('grades_processed.csv',encoding='utf-8') data.set_index('排名',inplace=True) data.head() ``` ```python # 利用Apriori算法进行关联分析 def createC1(dataSet): C1=[] for transaction in dataSet: for item in transaction: if not [item] in C1: C1.append([item]) C1.sort() return list(map(frozenset,C1)) def scanD(D,CK,minSupport): ssCnt = {} for tid in D: for can in CK: if can.issubset(tid): if not can in ssCnt:ssCnt[can]=1 else:ssCnt[can]+=1 numItems = float(len(D)) retList = [] supportData={} for key in ssCnt: support = ssCnt[key]/numItems if support>=minSupport: retList.insert(0,key) supportData[key]=support return retList,supportData #频繁项集两两组合 def aprioriGen(Lk,k): retList=[] lenLk = len(Lk) for i in range(lenLk): for j in range(i+1,lenLk): L1=list(Lk[i])[:k-2];L2=list(Lk[j])[:k-2] L1.sort();L2.sort() if L1==L2: retList.append(Lk[i]|Lk[j]) return retList def apriori(dataSet,minSupport=0.5): C1=createC1(dataSet) D=list(map(set,dataSet)) L1,supportData =scanD(D,C1,minSupport) L=[L1] k=2 while(len(L[k-2])>0): CK = aprioriGen(L[k-2],k) Lk,supK = scanD(D,CK,minSupport) supportData.update(supK) L.append(Lk) k+=1 return L,supportData #规则计算的主函数 def generateRules(L,supportData,minConf): bigRuleList = [] for i in range(1,len(L)): for freqSet in L[i]: H1 = [frozenset([item]) for item in freqSet] if(i>1): rulesFromConseq(freqSet,H1,supportData,bigRuleList,minConf) else: calcConf(freqSet,H1,supportData,bigRuleList,minConf) return bigRuleList def calcConf(freqSet,H,supportData,brl,minConf): prunedH=[] for conseq in H: conf = supportData[freqSet]/supportData[freqSet-conseq] if conf>=minConf: print (freqSet-conseq,'--->',conseq,'conf:',conf) brl.append((freqSet-conseq,conseq,conf)) prunedH.append(conseq) return prunedH def rulesFromConseq(freqSet,H,supportData,brl,minConf): m = len(H[0]) if (len(freqSet)>(m+1)): Hmp1 = aprioriGen(H,m+1) Hmp1 = calcConf(freqSet,Hmp1,supportData,brl,minConf) if(len(Hmp1)>1): rulesFromConseq(freqSet,Hmp1,supportData,brl,minConf) # 构建数据集 def creat(da): daset=[] for i in range(0, len(da)): perdaset=[] t = 0 for k in da.iloc[i]: if(k): perdaset.append(da.iloc[i].index[t]) t = t+1 daset.append(perdaset) return daset ``` ```python one = pd.concat([data['面向对象程序设计'],data['数据结构'],data['数据库原理'],data['信息论与编码技术'],data['计算机网络/专业核心课程/3'],data['计算机组成原理/专业核心课程/3']],axis=1) one.head() # 进行分析数据 dataSet=creat(one) L,supportData=apriori(dataSet) rules = generateRules(L,supportData,minConf=0.7) two = pd.concat([data['数据库原理'],data['计算机组成原理/专业核心课程/3'],data['密码学基础/专业核心课程/4'],data['信息安全概论/专业核心课程/2.5'],data['操作系统/专业核心课程/3']],axis=1) two.head() # 进行分析数据 dataSet=creat(two) L,supportData=apriori(dataSet) rules = generateRules(L,supportData,minConf=0.6) three = pd.concat([data['数据结构'],data['数据库原理'],data['操作系统/专业核心课程/3'],data['计算机网络/专业核心课程/3'],data['密码学基础/专业核心课程/4'],data['计算机组成原理/专业核心课程/3']],axis=1) three.head() # 进行分析数据 dataSet=creat(three) L,supportData=apriori(dataSet) rules = generateRules(L,supportData,minConf=0.7) one = pd.concat([data['面向对象程序设计'],data['数据结构'],data['数据库原理'],data['高等数学一'],data['高等数学(二)'],data['概率论与数理统计']],axis=1) one.head() # 进行分析数据 dataSet=creat(one) L,supportData=apriori(dataSet) rules = generateRules(L,supportData,minConf=0.7) two = pd.concat([data['面向对象程序设计'],data['数据结构'],data['数据库原理'],data['线性代数'],data['信息安全数学基础'],data['概率论与数理统计']],axis=1) two.head() # 进行分析数据 dataSet=creat(two) L,supportData=apriori(dataSet) rules = generateRules(L,supportData,minConf=0.7) three = pd.concat([data['信息论与编码技术'],data['密码学基础/专业核心课程/4'],data['高等数学一'],data['高等数学(二)'],data['线性代数'],data['概率论与数理统计']],axis=1) three.head() # 进行分析数据 dataSet=creat(three) L,supportData=apriori(dataSet) rules = generateRules(L,supportData,minConf=0.7) one = pd.concat([data['面向对象程序设计'],data['数据结构'],data['大学物理'],data['大学物理(二)'],data['数字逻辑'],data['数据通信原理']],axis=1) one.head() # 进行分析数据 dataSet=creat(one) L,supportData=apriori(dataSet) rules = generateRules(L,supportData,minConf=0.7) two = pd.concat([data['信息论与编码技术'],data['操作系统/专业核心课程/3'],data['密码学基础/专业核心课程/4'],data['计算机网络/专业核心课程/3'],data['数字逻辑'],data['数据通信原理']],axis=1) two.head() # 进行分析数据 dataSet=creat(two) L,supportData=apriori(dataSet) rules = generateRules(L,supportData,minConf=0.7) three = pd.concat([data['数据库原理'],data['计算机组成原理/专业核心课程/3'],data['大学物理'],data['大学物理(二)'],data['数字逻辑'],data['数据通信原理']],axis=1) three.head() # 进行分析数据 dataSet=creat(three) L,supportData=apriori(dataSet) rules = generateRules(L,supportData,minConf=0.7) ```
张龙
2024年8月15日 09:53
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码