数据技术应用概论
第一章 绪论
数据素质培养意义
数据技术
数据科学应用体系框架
第二章 计算机信息系统
计算机信息系统的构成
计算机信息系统技术路线
第三章 抽样技术
抽样技术概述
网络调查和社会调查
抽样学习
抽样技术的基本概念
第四章 网络爬虫与文本数据生成
网络爬虫概述
网络爬虫技术操作
文本数据生成
第五章 数据库技术
数据库技术概述
数据库系统开发
关系数据库
数据仓库
第六章 SQL语言
SQL概述
SQL关系定义
SQL查询基本结构
数据库修改
视图
第七章 数据预处理技术
数据预处理概述
数据清理
数据集成
数据规约
数据变换
第八章 回归模型
回归模型的基础知识
最小二乘法
其他常用回归模型
第九章 Logistic建模技术
基础知识
梯度上升算法
第十章 关联规则挖掘
关联规则挖掘的基础知识
关联规则挖掘的 Apriori 算法
其它常用关联规则挖掘算法
第十一章 决策树分类规则
决策树分类规则的基础知识
决策树分类规则挖掘的ID3算法
几种常用的决策树
第十二章 K-平均聚类
基础知识
基于划分的K‐平均聚类算法
其他常用的聚类
第十三章 神经网络模型
神经网络模型的基础知识
误差逆传播算法
其他常用的神经网络算法
第十四章 支持向量机
支持向量机的基础知识
支持向量机的SMO算法
其他常用的支持向量机算法
第十五章 集成学习算法
集成学习算法的基础知识
随机森林算法
其他常用的集成学习算法
第十六章 数据可视化
数据可视化的基础知识
可视化设计基础
数据可视化工具
-
+
首页
基础知识
## 9.1.1 问题提出 - `离散型数据`在实际应用中经常遇到。 例如,商品好坏、保险索赔次数、社会经济运行稳定与否等等都用离散型数据描述。 Logistic建模技术是`分析离散型数据的常用方法`之一。 - `二分类数据`是常见的离散型数据之一。 例如,下表给出了流动人口居留意愿的调查数据。 - 这里,居留意愿的取值为0或1。 1代表有长期居留意愿,0代表没有长期居留意愿。那么,居留意愿的观测数据就是二分类数据。 为了描述居留意愿的变化特征,需要考虑与居留意愿相关的因素。例如,家庭随迁人数是影响居留意愿的因素之一。 | 序号 | 家庭随迁人数 | 居留意愿 | 序号 | 家庭随迁人数 | 居留意愿 | | --- | --- | --- | --- | --- | --- | | 1 | 2 | 1 | 14 | 1 | 0 | | 2 | 2 | 0 | 15 | 2 | 1 | | 3 | 3 | 1 | 16 | 1 | 1 | | 4 | 1 | 0 | 17 | 1 | 0 | | 5 | 3 | 1 | 18 | 1 | 0 | | 6 | 1 | 1 | 19 | 1 | 1 | | 7 | 1 | 0 | 20 | 3 | 1 | | 8 | 1 | 0 | 21 | 2 | 1 | | 9 | 1 | 0 | 22 | 1 | 0 | | 10 | 1 | 0 | 23 | 1 | 0 | | 11 | 2 | 1 | 24 | 1 | 1 | | 12 | 2 | 1 | 25 | 3 | 1 | | 13 | 2 | 1 | 26 | 2 | 0 | - 记响应变量$$Y$$表示是否愿意长期居留, > ```latex Y\;=\;\left\{\begin{array}{l}1,\mathrm{有长期居留意愿}\\0,\mathrm{没有长期居留意愿}\end{array}\right. ``` - 解释变量$$X$$为家庭随迁人数。 预测流动人口居留意愿的Logistic模型为: > ```latex \log it\lbrack\pi(x)\rbrack\;=\;\beta_0\;+\;\beta_1x\;+\;\varepsilon ``` - 其中$$\beta_0, \beta_1$$为Logistic模型的回归系数;$$\varepsilon$$为随机误差项。 $$\pi(x) = P(Y=1)$$,表示在解释变量$$X$$取值为$$x$$时的“成功”概率,也就是,当流动人口的家庭随迁人数为x时,其有长期居留意愿的概率。 - 其中, > $$\log it\lbrack\pi(x)\rbrack\ = \log(P(Y=1)/P(Y=0))$$ - 表示当流动人口的家庭随迁人数为$$x$$时,有长期居留意愿的概率与无长期居留意愿的概率之比,称为`优势比`。 - 模型描述了家庭随迁人数X对长期居留意愿的影响。若$$\beta_1 > 0$$,表示随着家庭随迁人数X的增加,有长期居留意愿的概率越大,长期居留意愿越强。 **离散型数据的分类** - 二分类数据是常见的离散型数据之一。 离散型数据在科学研究和生产实践中非常普遍。 > 例如:男性表示为1,女性表示为2;那么人口性别数据由1和2组成。这类数据是离散型数据,相应的数字代表不同的类别;这类数据也叫`名义数据、类别数据、定类数据`。 - 还有一类数据,例如:奥运会游泳比赛,将产生的冠军、亚军和季军,可以依次用1、2、3表示。 成年人体重有偏轻、正常、偏重、超重,可以依次表示为1、2、3、4等。这些数据也是离散型数据。 特别地,它们不仅能够`描述不同类别,还能够描述类别的差异`,被称为`有序数据`。 - 不论是名义数据还是有序数据,都是将所研究的客观现象,按照某一标准能够划分为不同的类别,相应的类别用数字表示为离散型数据。 - 除次之外,还有另一类数据,如人口数、信用违约数、商品数量、航班数等都是定量数据,也是离散型数据,能够`描述客观现象出现的频繁程度`。 - 离散型数据有时简称为离散数据,是指自然数或者整数单位计量的数据。 一般来说,连续型数据分析方法并不总适用于分析离散型数据,常见的离散型数据是类别数据。 > 对于`只有两个类别`的情形,观测值只有两个,就是二分类数据, 例如:“成功”和“失败”,或“发生”和“不发生”,或“合格”和“不合格”等 **离散数据建模技术的研究进程** ```timeline # 20世纪早期 `Karl Pearson(卡尔.皮尔逊 )`引入列联表$$X^2$$检验用于检验双向列联表统计独立性。之后,Fisher完善了列联表$$X^2$$检验。`George Yule(尤尔)`定义了优势比度量列联表的关联性。 # 20世纪30年代,针对离散型数据的分析模型开始出现 - `Fisher`和`Frank Yates(耶茨)`提出了针对二分数据的二项参数变换,即 > $$log[\pi/(1-\pi)]$$ - ` Berkson(伯克森)`将这个变换称为logit,即对数优势比。之后,Logistic回归模型得到了广泛应用。 - `Rasch(拉什)`提出了具有个体和项目参数的Logit模型。现在称为拉什模型,该模型在心理学和教育学中获得了广泛应用。 - `麦克法登`发展了离散选择模型,并获得了2000年诺贝尔经济学奖。之后,`McCullagh(麦克莱)`给出了Fisher得分算法,累积Logit模型开始受到关注。 - 随后,内尔德和韦德伯恩引入广义线性模型的概念,并将二项响应的Logistic模型和Probit模型、针对泊松分布和负二项分布的对数线性模型,以及针对正态响应的回归模型和方差分析模型都归纳为广义线性模型。 - 近年来,针对聚簇数据的关联拟合Logistic模型和广义线性混合模 型受到更多关注。 # 20世纪中期 - `科克伦`给出了比较多个配对样本比例的一般性检验方法,提出了2*2*K列联表条件独立性的检验。 - `Goodman(古德曼)`将对数线性模型和Logit体模型应用于社会科学领域中分析多维离散数据。 # 2000年后,计算机技术发展和普及 - `Bayesian方法`重新受到关注,促使离散数据分析方法获得较大发展。 - 海量数据集对离散数据分析提出了新的挑战和发展机遇,推动了数据挖掘模型不断出现,新引入模型主要针对文本数据和图像数据,主要用于非结构化数据建模。 ==== ```` **Logistic回归模型的研究领域** - Logistic回归模型的应用领域包括:`社会科学、行为科学、生物医学、公共卫生、市场营销、教育和农业科学等`许多领域。 - 保险领域对事故发生率的预测,有助于保险公司制定更加合理的保费标准。 - 市场营销领域,通过市场搜集有关消费者偏好的数据,帮助商家更好地进行针对性营销,提高销量。 - 在社会学、行为学领域,对诸如流动人口居留意愿等个体选择问题的研究,可以增加对社会问题的了解。 **使用Logistic回归模型有几点问题需要注意:** 1. 不是所有的S型曲线关系都是Logistic回归形式,还有其他的S形曲线方程可供选择;例如下图中给出的probit曲线也是S形曲线: 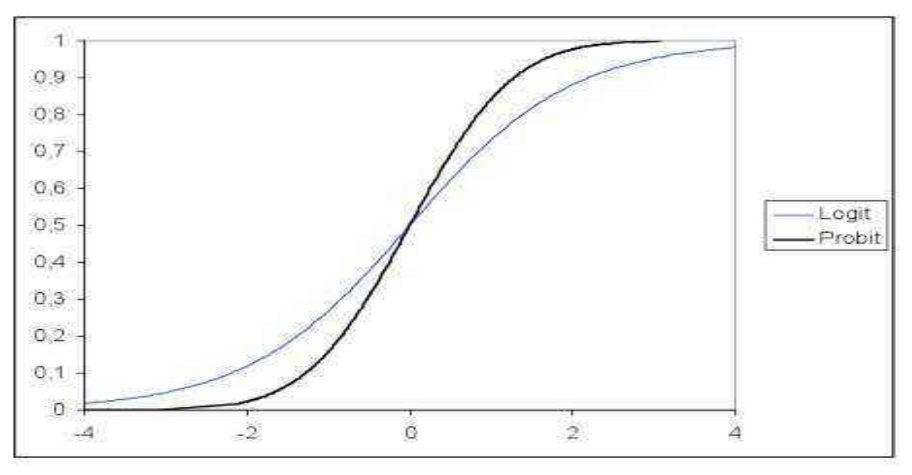 2. Logistic回归模型假定了自变量与因变量的Logit函数值呈`线性关系`,属于`广义线性模型`的一种;因此,在获得数据以后首先需要认真分析数据的特征,然后选择合适的、符合数据特征的模型估计。 ## 9.1.2 相关概率 - **相关概率**:Logistic 回归模型使用逻辑函数(Sigmoid 函数)将线性回归的输出转换为概率值,范围在0到1之间。逻辑函数定义如下: > $$ \sigma(z) = \frac{1}{1 + e^{-z}} $$ 其中,$$z$$ 是线性回归模型的输出,即 $$z = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + ... + \beta_n x_n$$,$$\beta$$ 是回归系数,$$x$$ 是特征变量。 - **逻辑函数的性质**: 当 $$z \to -\infty$$ 时,$$\sigma(z) \to 0$$。 当 $$z \to +\infty$$ 时,$$\sigma(z) \to 1$$。 当 $$z = 0$$ 时,$$\sigma(z) = 0.5$$。 逻辑函数将任意实数映射到 (0, 1) 区间,从而可以解释为概率。 ### 示例代码 - 使用本平台在线工具进行学习。 - 地址:首页->工作台[【快捷链接】](https://zenodt.com/workbench "【快捷链接】"),点击 _1717661367.png) 按钮,登录即可。 以下示例展示了如何使用 Python 和 Scikit-learn 库来构建和训练一个 Logistic 回归模型。 ```python import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # 生成一个示例数据集 np.random.seed(0) X = np.random.rand(100, 2) y = (X[:, 0] + X[:, 1] > 1).astype(int) # 数据集分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 创建和训练Logistic回归模型 model = LogisticRegression() model.fit(X_train, y_train) # 预测和评估模型 y_pred = model.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print(f"模型准确率: {accuracy:.2f}") # 输出逻辑函数的概率值 probs = model.predict_proba(X_test) print("预测概率值:") print(probs) ``` 该示例生成了一个随机数据集,将其用于训练 Logistic 回归模型,并输出模型的准确率和预测概率值。逻辑函数将线性回归的输出转换为概率,使我们能够预测事件发生的可能性。 ------------
张龙
2024年8月15日 09:40
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码