数据技术应用概论
第一章 绪论
数据素质培养意义
数据技术
数据科学应用体系框架
第二章 计算机信息系统
计算机信息系统的构成
计算机信息系统技术路线
第三章 抽样技术
抽样技术概述
网络调查和社会调查
抽样学习
抽样技术的基本概念
第四章 网络爬虫与文本数据生成
网络爬虫概述
网络爬虫技术操作
文本数据生成
第五章 数据库技术
数据库技术概述
数据库系统开发
关系数据库
数据仓库
第六章 SQL语言
SQL概述
SQL关系定义
SQL查询基本结构
数据库修改
视图
第七章 数据预处理技术
数据预处理概述
数据清理
数据集成
数据规约
数据变换
第八章 回归模型
回归模型的基础知识
最小二乘法
其他常用回归模型
第九章 Logistic建模技术
基础知识
梯度上升算法
第十章 关联规则挖掘
关联规则挖掘的基础知识
关联规则挖掘的 Apriori 算法
其它常用关联规则挖掘算法
第十一章 决策树分类规则
决策树分类规则的基础知识
决策树分类规则挖掘的ID3算法
几种常用的决策树
第十二章 K-平均聚类
基础知识
基于划分的K‐平均聚类算法
其他常用的聚类
第十三章 神经网络模型
神经网络模型的基础知识
误差逆传播算法
其他常用的神经网络算法
第十四章 支持向量机
支持向量机的基础知识
支持向量机的SMO算法
其他常用的支持向量机算法
第十五章 集成学习算法
集成学习算法的基础知识
随机森林算法
其他常用的集成学习算法
第十六章 数据可视化
数据可视化的基础知识
可视化设计基础
数据可视化工具
-
+
首页
支持向量机的基础知识
## 1.问题提出 >- 支持向量机:支持向量(Support Vector Machine,SVM)机的思想是Vapnik等于1963年在解决模式识别问题时提出的。1 9 7 1年,Kimeldorf提出了基于支持向量构建核空间的方法。1992年,Vapnik和Boser及Guyon将核函数应用于最大分隔超平面上,创建非线性分类器。目前,常用的“软间隔”支持向量机算法是由Cortes和Vapnik提出,正式发表于1995年 >- 应用领域:目前,支持向量机应用领域已非常广泛。支持向量机已应用于网页或文本自动分类、人脸检测、计算机入侵检测、基因分类、图像分类、遥感图象分析、语音识别、信息安全、目标识别、文本过滤、非线性系统控制等领域 - `假设特征空间是二维的,一个数据样本集是线性可分的,是指存在一条直线,可以把这两类数据分开。各个训练样本在特征空间中的分布如下图所示,存在一条直线将这两个类别区分开。` 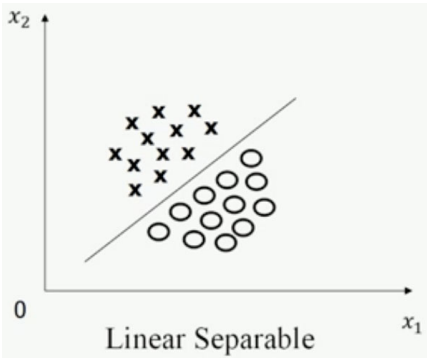 - `数据样本集是非线性可分的,是指不存在一条直线,可以把这两类数据分开。把控下图所示` 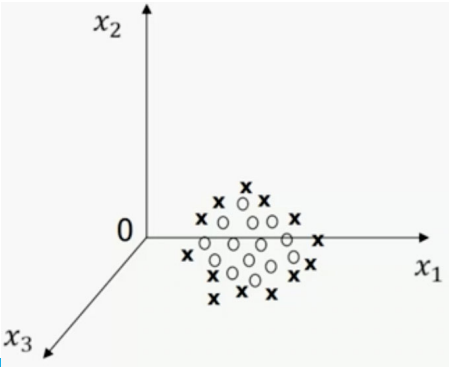 - `同样可以扩展到三维空间的情况。如下图所示,特征空间是三维时,线性可分的例子` 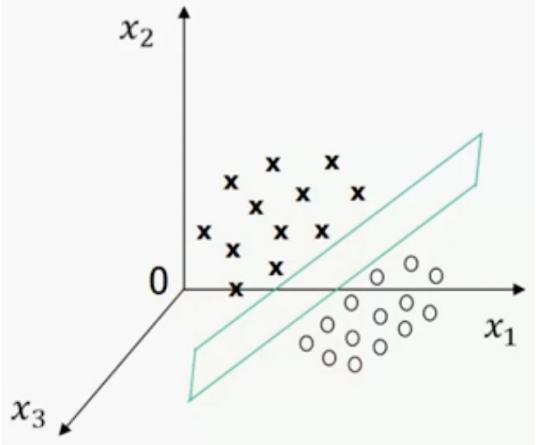 - `如下图所示是特征空间三维时线性不可分例子。` 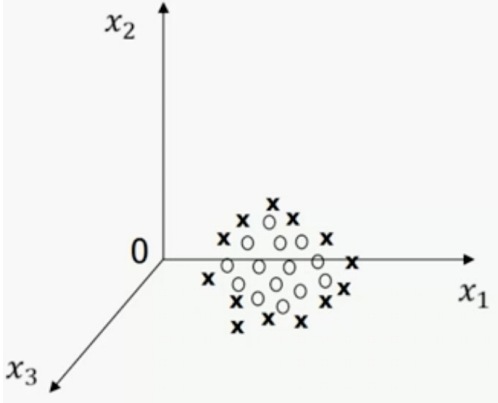 ------------ 同样,可以扩展到`特征空间>=3维`的情况。借助数学给出精确的定义。 假设给定一个特征空间上的训练数据集有N个训练样本和他们的标签 $$T=$${$$(x_1,y_1),(x_2,y_2)....(x_N,y_N)$$},其中,$$y_i\in$${+1,-1} $$x_i$$为第i个实例,(若n>1,$$x_i$$为向量);$$y_i$$为$$x_i$$的类标记;($$x_i$$,$$y_i$$)称为样本点 - 线性可分的定义: 对于一个训练数据集$$T=$${$$(x_1,y_1),(x_2,y_2)....(x_N,y_N)$$},线性可分,是指存在($$\omega_1,\omega_2,\omega_0$$),使得 >当$$y_i=+1$$时,$$\omega_1x_1+\omega_2x_2+\omega_0>0$$ 当$$y_i=-1$$时,$$\omega_1x_1+\omega_2x_2+\omega_0<0$$ - 用向量的形式来定义如下 >当$$y_i=+1$$时,$$\omega_0+\omega^Tx>0$$ 当$$y_i=-1$$时,$$\omega_0+\omega^Tx<0$$ 由于$$y_i\in$${+1,-1},上面两个公式可以统一成一个公式, 即对于训练数据集$$T=$${$$(x_1,y_1),(x_2,y_2)....(x_N,y_N)$$},线性可分,是指存在($$\omega,\omega_0$$),使得$$y_i(\omega_0+\omega^TX_i)>0$$ - 针对数据分布具有线性可分和线性不可分的特性,Vapnik提出的支持向量机算法分成两个步骤: (1)解决样本线性可分问题; (2)再将线性可分问题中获得的结论推广到线性不可分情况。 ------------ - 为了直观理解支持向量机算法,构造数据集D作为训练集,包括6个样本点,分别为 ($$x_1$$=(2,1),$$y_1$$=-1),($$x_2$$=(3,5),$$y_2$$=+1),($$x_3$$=(3,2),$$y_3$$=-1), ($$x_4$$=(2,2),$$y_4$$=-1),($$x_5$$=(4,4),$$y_5$$=+1),($$x_6$$=(4,5),$$y_6$$=+1) 其中,变量y是类别变量,包括2个类别,分别用+1和-1表示。存在多条直线可以将2个类别的样本点分开,如图中的直线1、2、3,到底哪条线是最好的呢? 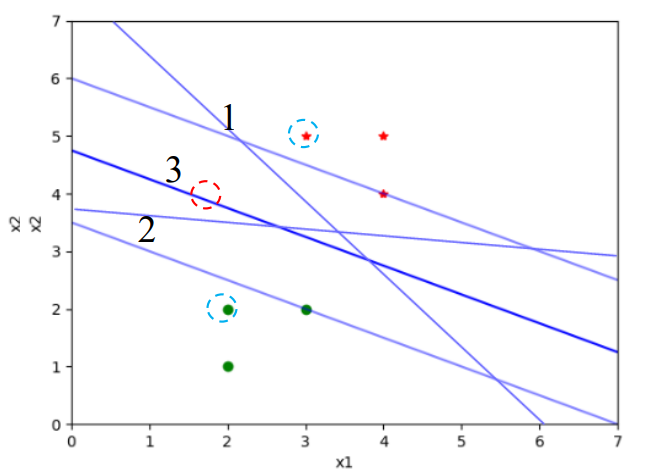 - 基于最优化理论 ,寻找3号线的过程转化为最优化问题。支持向量机算法最大化两个类别样本在特征空间上的间隔。两条虚线之间的距离称为间隔。虚线所经过的样本称为“支持向量”,支持向量机要找的是使得“间隔”最大的那条直线。扩展到高维空间,支持向量机构造可以最大化间隔的分离超平面。 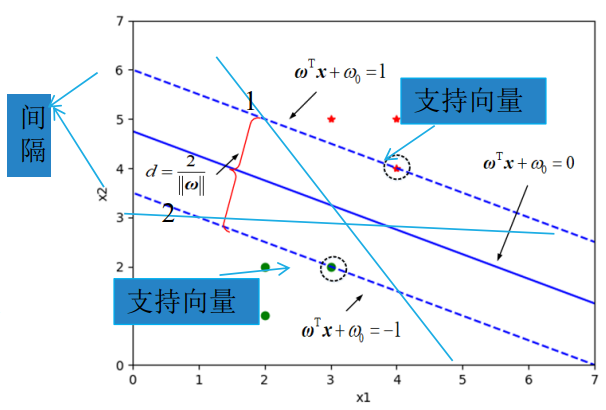 - 所以,支持向量机寻找的最优分类直线应该满足以下三个条件: >(1)该直线应该分开两个类 (2)该直线应该最大化间隔 (3)该直线处于间隔的中间,到所有支持向量的距离相等 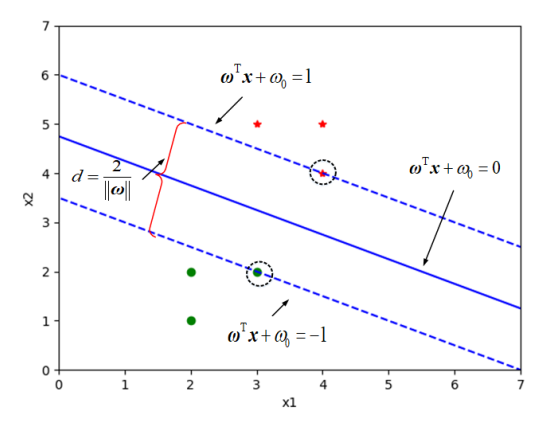 ## 2.相关概念 ### 1.分隔超平面 `给定数据集及其所在的空间,分隔超平面可用如下线性方程来描述:` - 偏移量,决定了超平面与原点之间的距离; $$\omega_0+\omega^Tx=0$$,$$\omega_0$$ - 法向量,决定了超平面的方向; $$\omega=(\omega_1,\omega_2....\omega_p)$$ 分隔超平面被位移$$\omega_0$$和法向量$$\omega$$唯一确定,将其简单记为$$\omega,\omega_0$$ 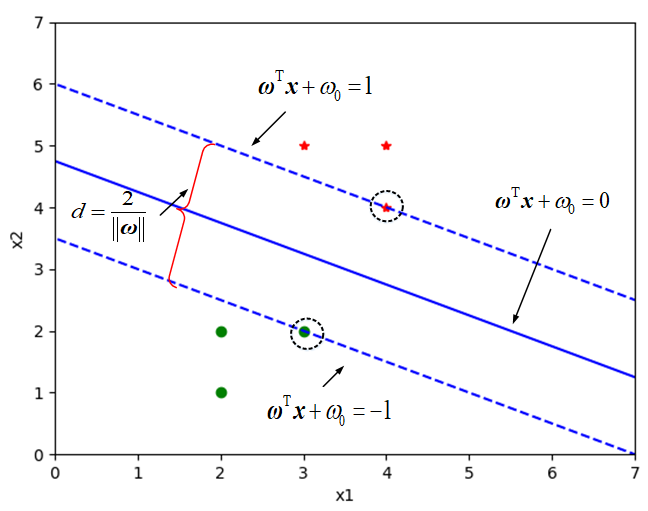 ### 2.支持向量 超平面$$\omega,\omega_0$$能将训练样本正确分类,也意味着对于任意的$$(x_i,y_i)\in D$$, >若$$y_i=+1$$,有$$\omega_0+\omega^Tx>0$$ >若$$y_i=-1$$,有$$\omega_0+\omega^Tx<0$$。 令 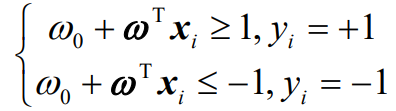 距离超平面$$\omega,\omega_0$$最近的训练样本点,用圆圈标注,使上式的等号成立,称为“支持向量”(support vector)。 一个点$$x_0$$到超平面$$\omega^Tx_0+\omega_0=0$$的距离 ### 3.最大分类间隔 在样本点的空间里,记$$||\omega||$$是欧几里得数,任意样本点(x,y)到超平面的距离$$\omega,\omega_0$$最少为$$1/||\omega||$$最大分类间隔为从支持向量到超平面距离之和,即为$$d=2/||\omega||$$ ### 4.线性可分支持向量机 支持向量机模型寻找具有“最大间隔”(ma ximum margin)的分隔超平面,即满足分类约束,使得分类间隔 d 达到最大时的参数$$\omega$$和$$\omega_0$$,也就是  对于限制条件,支持向量$$|\omega^Tx_0+\omega|=1$$,而非支持向量$$|\omega^Tx_0+\omega|>1$$, ,由于$$y_i\in$${+1,-1}综合两者就可以得到限制条件:$$y_i(\omega^Tx_0+\omega)\geq1,i=1,2,...m$$ 求解式(4);得到最大间隔分隔超平面$$f(x)=\omega^Tx_0+\omega$$, 其中$$\omega,\omega_0$$是模型参数。 ------------ ## 小结 - 支持向量机(support vector machine,SVM)是一种分类算法,适用于二分类问题,也适用于多分类问题。支持向量机算法的关键是构造线性分类器,寻找最优分隔超平面,尽可能区分开两个类别的样本,使得不同类别的样本与该分隔超平面的距离最大。 - 支持向量机的学习方法主要有三种:  - 支持向量机在解决小样本、非线性及高维模式识别中表现出许多特有优势。SVM致力于寻找划分特征空间的最优超平面,使得分类间隔达到最大。在SVM分类决策中起决定作用的是支持向量,SVM的最优分类函数只由少数的支持向量所确定,计算复杂性取决于支持向量的数目,而不是样本量和样本空间维数。优化目标函数是结构化风险最小,不是经验风险最小。通过“间隔”的概念,对样本点散布的结构化描述,放宽了对样本规模和样本分布的要求。对于非线性可分问题,SVM利用核函数向高维空间的非线性映射。当核函数已知时,可以简化高维空间问题的求解难度。
张龙
2024年7月22日 15:11
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码